Bayesian Statistics
Chapter C Solutions to exercises
Chapter 1
-
-
(a) Samples of \(X\) will tend to be in one of three different locations: (1) sharply clustered around \(-7.5\), (2) a broad cluster between approximately \([-4,4]\) and (3) close to \(10\), but not greater than \(10\).
-
(b) We have
\[\int _\R f_{X_\theta }(x)\,dx=\int _1^\infty (\theta -1)x^{-\theta }\,dx =\l [(\theta -1)\frac {x^{1-\theta }}{1-\theta }\r ]_{x=1}^\infty =1\]
as required.
-
-
1.2 Neither.
To see that \(Z\) is not continuous: recall that for any continuous random variable \(Z'\) we have \(\P [Z'=z]=0\) for all \(z'\). However, \(\P [Z=0]=\P [Y=0]+\P [Y=1,X=0]=\frac 12+\frac 12(0)=\frac 12\).
To see that \(Z\) is not discrete: note that \(Z\) takes values across all of \(\R \), coming from the case where \(Y=1\), which has probability \(\frac 12\).
-
-
(a) \(U'\) has the conditional distribution of \(U\) given the event \(\{U\in [a,b]\}\).
-
(b) We apply Lemma 1.4.1 with \(A=[a,b]\). Part 1 gives that \(\P [U'\in [a,b]]=1\). Part 2 gives that for all \(B\sw [a,b]\) we have
\[\P [U'\in B] =\frac {\P [U\in B]}{\P [U\in A]} =\frac {\int _B \frac {1}{c-a}\,dx}{\int _a^b\frac {1}{c-a}\,dx} =\frac {\int _B \frac {1}{c-a}\,dx}{\frac {b-a}{c-a}} =\int _B \frac {1}{b-a}\,dx.\]
Hence \(U'\) is a continuous random variable with p.d.f.
\[f_{U'}(u)=\begin {cases} \frac {1}{b-a} & \text { for }x\in [a,b] \\ 0 & \text { otherwise}. \end {cases} \]
This is the continuous uniform distribution on \([a,b]\).
-
(c) We have:
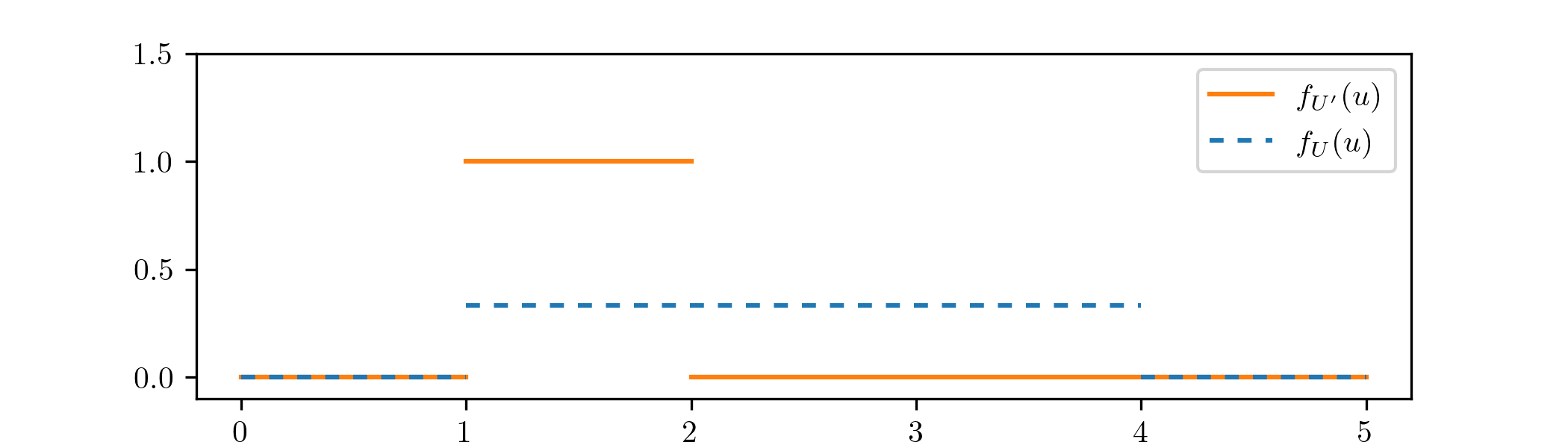
-
-
1.4 Suppose that \(G\) has the \(\Geo (p)\) distribution, that is \(\P [G=g]=p^{g-1}(1-p)\) for \(g\in \{1,\ldots \}\), where \(p\in [0,1]\). Let \(G'\eqd G|_{\{G\geq n\}}\), where \(n\in \N \).
-
(a) We apply Lemma 1.4.1 with \(A=\{n,n+1,\ldots \}\). From part 1 of the lemma we have \(\P [G'\in \{n,n+1,\ldots ,\}]=1\). From part 2, for \(g\in \{n,n+1,\ldots \}\) we have
\[\P [G'=g] =\frac {\P [G=g]}{\P [G\in A]} =\frac {p^{g}(1-p)}{\sum _{k=n}^\infty p^{k}(1-p)} =\frac {p^{g}(1-p)}{(1-p)\sum _{k=n}^\infty p^k} =\frac {p^{g}(1-p)}{(1-p)\frac {p^{n}}{1-p}} =p^{g-n}(1-p) \]
-
(b) The claim is correct. For \(g\in \{n,n+1,\ldots ,\}\), the \(-n\) term in \(p^{g-n}\) above corresponds to removing the factors \(p\) corresponding to success/failure of the first \(n\) trials, from what would otherwise have been \(p^{g}\) in the p.m.f. of \(G\).
-
-
1.5 You should notice that as \(n\) gets larger it takes longer to obtain samples, and it quickly becomes impractical to do so as \(n\) grows large. This is because it becomes more likely that samples fall into \((-\infty ,n)\) and are rejected, so it takes longer to find a sample that is accepted.
-
-
(a) We have
\[ \sum _{y=1}^\infty \sum _{x=1}^\infty 2^{-xy}(1-2^{-y}) =\sum _{y=1}^\infty (1-2^{-y})\sum _{x=1}^\infty (2^{-y})^x =\sum _{y=1}^\infty (1-2^{-y})\frac {2^{-y}}{1-2^{-y}} =\sum _{y=1}^\infty 2^{-y}=\frac {1/2}{1-1/2}=1 \]
as required. Here we use that the summations are geometric sums.
The random variables \(X\) and \(Y\) are not independent because (1.14) does not factorise into the form \(g(x)h(y)\).
-
(b)
-
(i) To find the marginal distribution of \(Y\) we sum over all possible values of \(x\), giving
\[\P [Y=y] =\sum _{x=1}^\infty 2^{-xy}(1-2^{-y}) =(1-2^{-y})\sum _{x=1}^\infty (2^{-y})^x =(1-2^{-y})\frac {2^{-y}}{1-2^{-y}} =\l (\frac {1}{2}\r )^y\]
for \(y\in \N \).
-
(ii) Using Lemma 1.5.1 we have
\[\P [X|_{\{Y=5\}}=x] =\frac {\P [X=x,Y=5]}{\P [Y=5]} =\frac {2^{-5x}(1-2^{-5})}{2^{-5}} =\l (1-\frac {1}{2^5}\r )\l (\frac {1}{2^5}\r )^{x-1}.\]
In the middle equality we use (1.14) and part (a).
-
(iii) Again using Lemma 1.5.1 we have
\(\seteqnumber{0}{C.}{0}\)\begin{equation} \label {eq:cond_corr_ps_xy} \P [Y|_{\{X\geq 5\}}=y] =\frac {\P [X\geq 5,Y=y]}{\P [X\geq 5]}. \end{equation}
We need to calculate the top and bottom of (C.1). For \(y\in \N \),
\(\seteqnumber{0}{C.}{1}\)\begin{align*} \P [X\geq 5, Y=y] &=\sum _{x=5}^\infty 2^{-xy}(1-2^{-y}) \\ &=(1-2^{-y})\sum _{x=5}^\infty (2^{-y})^x =(1-2^{-y})\frac {(2^{-y})^5}{1-2^{-y}} =2^{-5y}. \end{align*} Hence \(\P [X\geq 5] =\sum _{y=1}^\infty 2^{-5y} =\sum _{y=1}^\infty (2^{-5})^y =\frac {2^{-5}}{1-2^{-5}}.\) Putting these into (C.1) we obtain
\(\seteqnumber{0}{C.}{1}\)\begin{align*} \P [Y|_{\{X\geq 5\}}=y] = \frac {2^{-5y}(1-2^{-5})}{2^{-5}} = \l (1-\frac {1}{2^5}\r )\l (\frac {1}{2^5}\r )^{y-1} \end{align*} for \(y\in \N \).
The distributions found in (b) are all Geometric distributions. They have range \(\{1,2,\ldots ,\}\) rather than \(\{0,1,\ldots ,\}\) i.e. using the alternative parametrization mentioned on the reference sheet.
-
-
-
1.7 Let \(X\in \Normal (0,1)\) and set \(A=[0,\infty )\), as in Example 1.4.3. Let \(Y'=|X|\). Show that \(Y'\eqd X|_{\{X\in A\}}\).
Note that \(\P [Y'\geq 0]=1\). For \(y> 0\) we can calculate,
\[\P [Y'\leq y] =\P [X\geq -y\text { or }X\leq y] =\int _{-y}^y f_X(x)\,dx =\int _{-y}^0 f_X(x)\,dx + \int _0^y f_X(x)\,dx =2\int _0^y f_X(x).\]
The last equality follows by symmetry (or a \(v=-y\) substitution) because \(f_X(x)=f_X(-x)\). Differentiating, for \(y>0\) we have \(f_{Y'}(y)=2f_X(y)\). Hence \(Y'\) is a continuous random variable with p.d.f.
\[f_{Y'}(y)=\begin {cases} 2f_X(y) & \text { for }y>0 \\ 0 & \text { otherwise}. \end {cases} \]
This matches the distribution of \(X|_{\{X\geq 0\}}\) that we obtained in Example 1.4.3.
-
1.8 From part 2 of Lemma 1.4.1, for \(B\sw A\) we have
\[\P [X|_{\{X\in A\}}\in B] =\frac {\P [X\in A\cap B]}{\P [X\in A]} =\frac {\P [X\in B]}{\P [X\in A]} =\frac {\int _{B}f_X(x)\,dx}{\P [X\in A]} =\int _{B}\frac {f_X(x)}{\P [X\in A]}\,dx.\]
By part 1 of Lemma 1.4.1 we have \(\P [X|_{\{X\in A\}}\in B]=1\). By Definition 1.1.1 \(X\) is a continuous random variable with p.d.f.
\[f_{X|_{\{X\in A\}}}(x)= \begin {cases} \frac {f_X(x)}{\P [X\in A]} & \text { if } x\in A \\ 0 & \text {otherwise.} \end {cases} \]
-
1.9 Let us write \(\mc {L}_X(A)=\P [X\in A]\) for the law of \(X\).
For the ‘if’ part, suppose that \(X\eqd Y\). Take \(A=\{x\}\) in Definition 1.2.1, where \(x\in R\), then \(\mc {L}_X(\{x\})=\P [X\in \{x\}]=\P [X=x]=p_X(x)\), and similarly for \(Y\). Since \(\mc {L}_X=\mc {L}_Y\) we have \(p_X(x)=p_Y(x)\).
For the ‘only if’ part, suppose that \(p_X(x)=p_Y(x)\) for all \(x\in R^d\). Note that for any \(A\sw \R ^d\) we have \(\mc {L}_X(A)=\P [X\in A]=\sum _{x\in A}\P [X=a]=\sum _{x\in A}p_X(x)\), and similarly for \(Y\). Hence \(\mc {L}_X(A)=\mc {L}_Y(A)\).
-
1.10 Suppose that \(X\) takes values in \(\R ^n\) and \(Y\) takes values in \(\R ^d\). We apply Lemma 1.4.1, conditioning \((X,Y)\) to be inside the set \(A\times \R ^d\). By part 2 of that lemma, for all \(B\sw \R ^d\) we have
\(\seteqnumber{0}{C.}{1}\)\begin{equation} \label {eq:indep_conditioning_1} \P [(X,Y)\in A\times B] =\frac {\P [(X,Y)\in A\times B]}{\P [(X,Y)\in A\times \R ^d]} =\frac {\P [X\in A, Y\in B]}{\P [X\in A]} =\frac {\P [X\in A]\P [Y\in B]}{\P [X\in A]} =\P [Y\in B], \end{equation}
where we have used the fact that \(X\) and \(Y\) are independent. By part 1 of the lemma we have \(\P [(X,Y)|_{\{X\in A\}}\in A\times \R ^d]=1\), which since \((X,Y)|_{\{X\in A\}}=(X|_{\{X\in A\}}, Y|_{\{X\in A\}})\) means that \(\P [X|_{\{X\in A\}}\in A]=1\). Hence, for all \(B\sw \R ^d\)
\[\P [Y|_{\{X\in A\}}\in B] =\P [X|_{\{X\in A\}}\in A\text { and }Y|_{\{X\in A\}}\in B] =\P [(X,Y)|_{\{X\in A\}}\in A\times B]=\P [Y\in B].\]
The last equality above uses (C.2). Thus \(Y\eqd Y|_{\{X\in A\}}\).
Chapter 2
-
2.1 See 2_dist_sketching_solution.ipynb or 2_dist_sketching_solution.Rmd
-
-
(a) \(\P [M_p=n]=p(1-p)^{n}\) for \(n\in \{1,2,\ldots ,\}\).
-
(b) From Theorem 2.4.1 the posterior distribution is given by
\(\seteqnumber{0}{C.}{2}\)\begin{align*} f_{P|_{\{X=5\}}}(p) &=\frac {1}{\int _0^1 \P [\Geo (q)=5]f_{\Unif ([0,1])}(q)\,dq}\P [\Geo (p)=5]f_{\Unif ([0,1])}(p)\,dp \\ &=\frac {1}{\int _0^1 q(1-q)^5\,dq}p(1-p)^5 \\ &=\frac {1}{\mc {B}(2,6)}p(1-p)^5 \end{align*} for \(p\in [0,1]\) and zero elsewhere, which we recognize as the p.d.f. of \(\Beta (2,6)\).
-
(c) We obtain
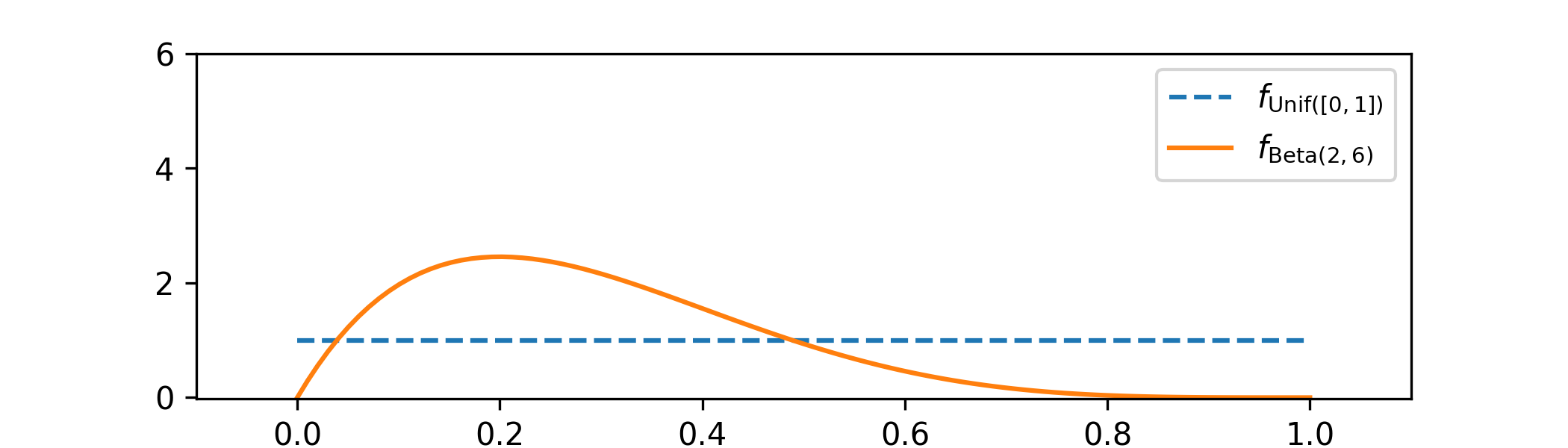
-
(d) From Theorem 2.4.1, now with the prior taken as \(P\sim \Beta (2,6)\) and the new data point \(x=9\), the posterior distribution is given by
\(\seteqnumber{0}{C.}{2}\)\begin{align*} f_{P|_{\{X=9\}}}(p) &=\frac {1}{\int _0^1 \P [\Geo (q)=9]f_{\Beta (2,6)}(q)\,dq}\P [\Geo (p)=9]f_{\Beta (2,6)}(p)\,dp \\ &=\frac {\mc {B}(2,6)}{\mc {B}(2,6)}\frac {1}{\int _0^1 q(1-q)^5q(1-q)^9q\,dq}p(1-p)^5p(1-p)^9 \\ &=\frac {1}{\mc {B}(3,15)}p^2(1-p)^{14} \end{align*} which we recognize as the p.d.f. of \(\Beta (3,15)\). Including this into our graph from (c),
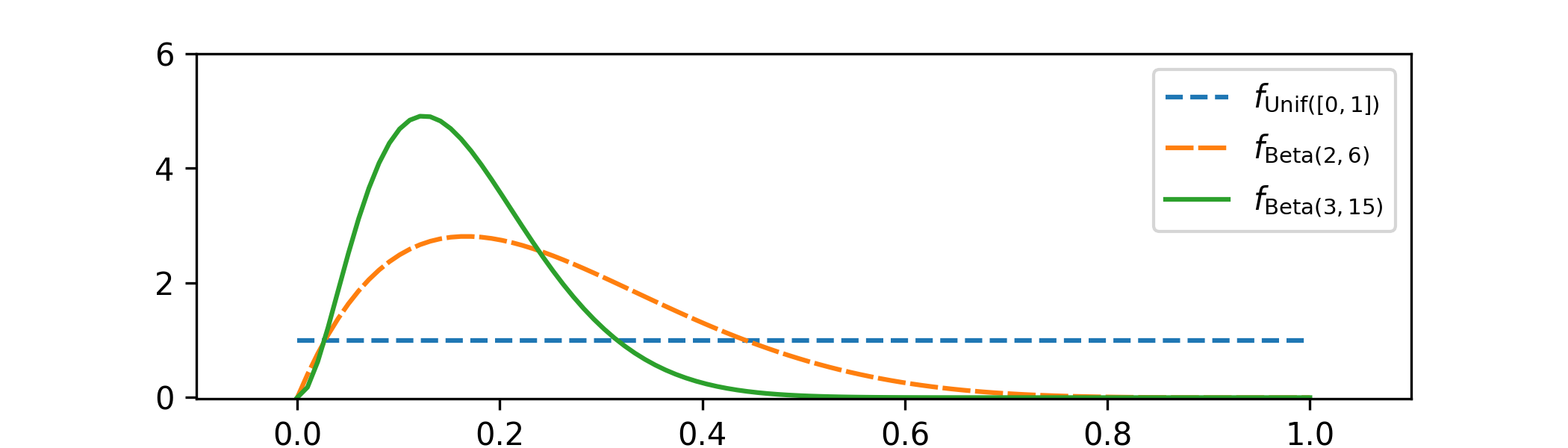
-
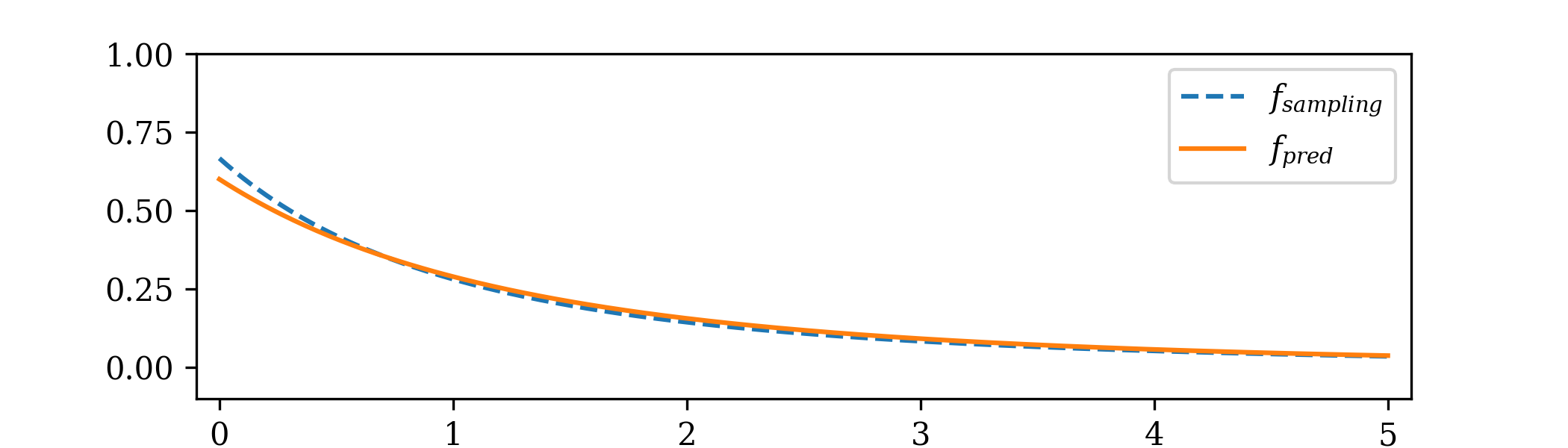
(e) The p.m.f. of the predictive distribution is
\[\P [X'=x']=\int _0^1 \P [{\Geo (p)}=x']f_{\Beta (3,15)}(p)\,dp\]
for \(x'\in \{0,1,\ldots \}\). We sketch this:
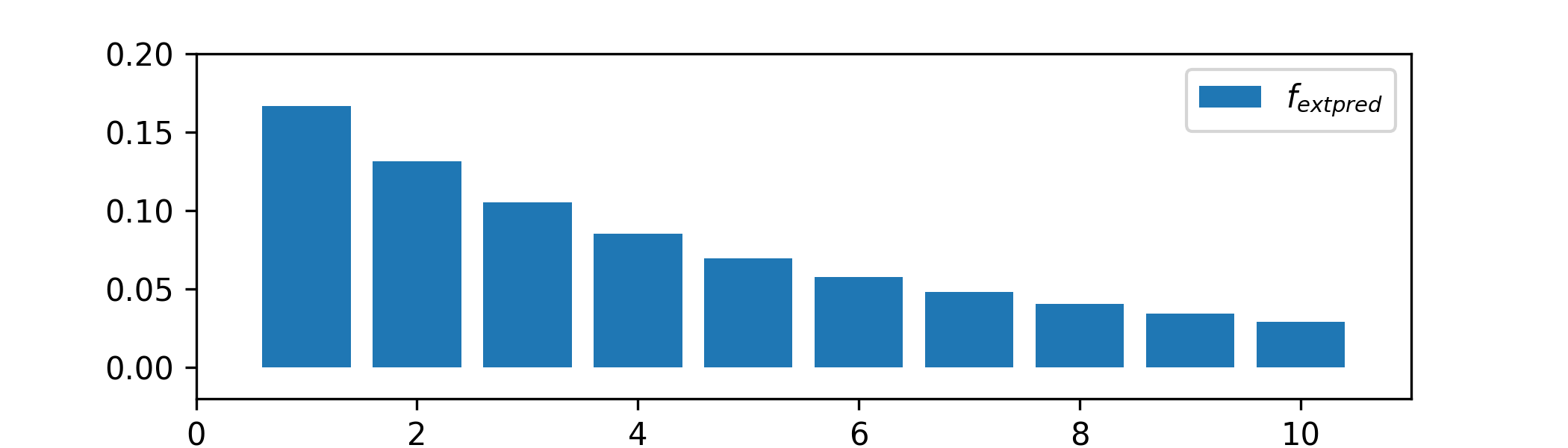
-
-
2.3 From Theorem 2.4.1 the posterior has p.d.f.
\(\seteqnumber{0}{C.}{2}\)\begin{align*} f_{\Lambda |_{\{X=5\}}}(\lambda ) &=\frac {1}{\int _0^\infty \P [\Poisson (l)=7]f_{\Exp (5)}(l)\,dl}\P [\Poisson (\lambda )=7]f_{\Exp (5)}(\lambda ) \\ &=\frac {7!}{7!}\frac {1}{\int _0^\infty l^7e^{-l}5e^{-5l}\,dl}\lambda ^7 e^{-\lambda }5 e^{-5\lambda } \\ &=\frac {1}{\int _0^\infty l^7e^{-6l}\,dl}\lambda ^7e^{-6\lambda } \\ &=\frac {6^8}{\Gamma (8)}\frac {1}{\int _0^\infty \frac {6^8}{\Gamma (8)}l^7e^{-6l}\,dl} \lambda ^8e^{-6\lambda }\\ &=\frac {6^8}{\Gamma (8)}\frac {1}{\int _0^\infty f_{\Gam (6,8)(l)}\,dl} \lambda ^7e^{-6\lambda }\\ &=\frac {6^8}{\Gamma (8)}\lambda ^7e^{-6\lambda } \end{align*} for \(\lambda >0\) and zero otherwise. We recognize this as the p.d.f. of the \(\Gam (8,6)\) distribution.
The predictive p.m.f. is given by
\(\seteqnumber{0}{C.}{2}\)\begin{align*} \P [X'=x] &=\int _0^\infty \P [\Poisson (\lambda )=x]f_{\Gam (8,6)}(\lambda )\,d\lambda \\ &=\int _0^\infty \frac {\lambda ^{x}e^{-\lambda }}{x!}\frac {8^6}{\Gamma (8)}\lambda ^7e^{-6\lambda }\,d\lambda \\ &=\frac {8^6}{7! x!}\int _0^\infty \lambda ^{7+x}e^{-7\lambda }\,d\lambda . \end{align*} for \(x\in \{0,1,\ldots \}\).
-
-
(a) For \(A\sw (0,1)\) we have
\(\seteqnumber{0}{C.}{2}\)\begin{align*} \P [X=n,Y\in A] &= \sum _{n=0}&\infty \P [X=n,Y\in A] \\ &= \frac {1}{Z}\sum _{n=0}^\infty \int _A e^{-y} y^n (1-y)^2 \frac {1}{n!}\, dy \\ &= \frac {1}{Z}\int _A e^{-y}(1-y)^2 \sum _{n=0}^\infty \frac {e^{-y}y^n}{n!}\, dy \\ &= \frac {1}{Z}\int _A (1-y)^2 \, dy. \end{align*} Taking \(A=(0,1)\) we have \(1=\frac {1}{Z}\int _0^1(1-y)^2\,dy=\frac {1}{Z}\frac {1}{27}\), which gives \(Z=\frac {1}{27}\) and
\[f_Y(y)=\begin {cases} 27 (1-y)^2 & \text { for }y\in (0,1) \\ 0 & \text { otherwise.} \end {cases}\]
We recognize the distribution \(Y\sim \Beta (1,3)\).
-
(b) Using part (a) we have
\(\seteqnumber{0}{C.}{2}\)\begin{align*} \P [X=n,Y\in A] =\int _A \frac {e^{-y}y^n}{n!}f_Y(y)\,dy =\int _A\P [\Poisson (y)=n]f_{\Beta (1,3)}(y)\,dy. \end{align*} Hence \((X,Y)\) is a Bayesian model with prior \(Y\sim \Beta (1,3)\) and model family \(X|_{\{Y=y\}}\sim \Poisson (y)\). In particular, the last part solves the question.
-
Chapter 3
-
3.1 See 2_dist_sketching_solution.ipynb or 2_dist_sketching_solution.Rmd
-
-
(a) From Theorem 3.1.2 the posterior distribution has p.d.f.
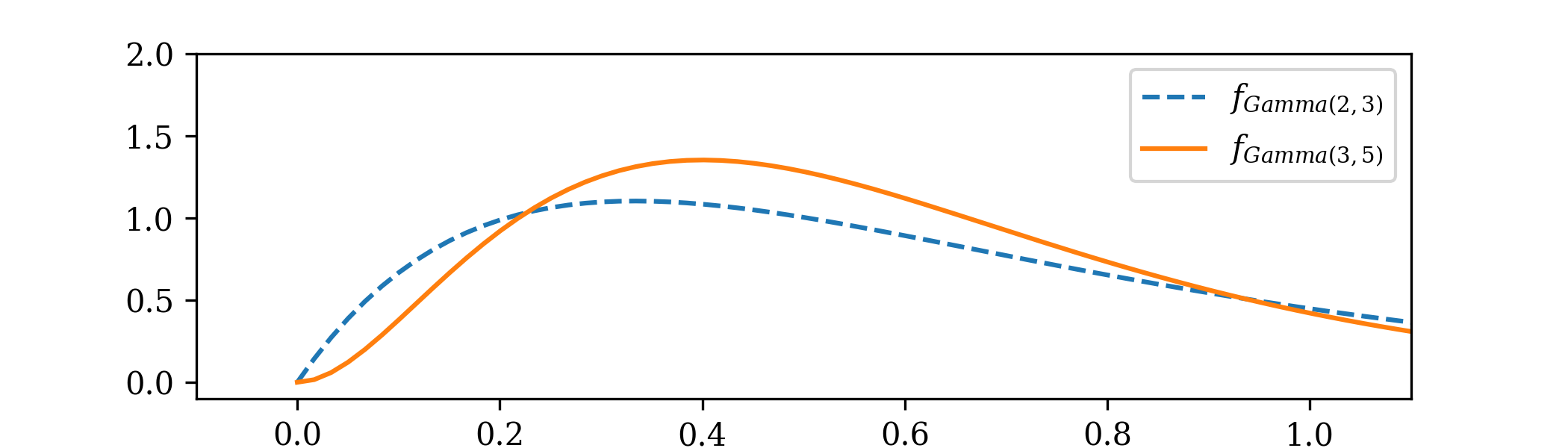
\(\seteqnumber{0}{C.}{2}\)\begin{align*} f_{\Theta |_{\{X=2\}}} &=\frac {1}{Z} f_{\Exp (\theta )}(2)f_{\Gam (2,3)}(\theta ) \\ &=\frac {1}{Z}\frac {3^2}{\Gamma (2)} \theta e^{-2\theta }\theta e^{-3\theta } \\ &=\frac {1}{Z'}\theta ^2 e^{-5\theta } \end{align*} for \(\theta >0\) and zero otherwise, where \(\frac {1}{Z'}=\frac {1}{Z}\frac {3^2}{\Gamma (2)}\). We recognize \(\Theta |_{\{X=2\}}\sim \Gam (3,5)\).
-
(b) From (3.2) the sampling distribution has p.d.f.
\(\seteqnumber{0}{C.}{2}\)\begin{align*} f_{X}(x) &=\int _0^\infty f_{\Exp (\theta )}(x)f_{\Gam (2,3)}(\theta )\,d\theta \\ &=\frac {3^2}{\Gamma (2)}\int _0^\infty \theta e^{-\theta x}\theta e^{-3\theta }\,d\theta \\ &=9\int _0^\infty \theta ^2 e^{-\theta (x+3)}\,d\theta \\ &=9\frac {2}{(x+3)^3}\int _0^\infty \frac {(x+3)^3}{2}\theta ^2 e^{-\theta (x+3)}\,d\theta \\ &=9\frac {2}{(x+3)^3}\int _0^\infty f_{\Gam (3,x+3)}(\theta )\,d\theta \\ &=\frac {18}{(x+3)^3} \end{align*} for \(x>0\) and zero otherwise.
From (3.5) and part (a), the corresponding predictive distribution has p.d.f.
\(\seteqnumber{0}{C.}{2}\)\begin{align*} f_{X'}(x) &=\int _0^\infty f_{\Exp (\theta )}(x)f_{\Gam (3,5)}(\theta )\,d\theta \\ &=\frac {5^3}{\Gamma (3)}\int _0^\infty \theta e^{-\theta x}\theta ^2 e^{-5\theta }\,d\theta \\ &=\frac {5^3}{2}\int _0^\infty \theta ^3 e^{-\theta (x+5)}\,d\theta \\ &=\frac {5^3}{2}\frac {\Gamma (4)}{(x+5)^4}\int _0^\infty \frac {(x+5)^4}{\Gamma (4)}\theta ^3 e^{-\theta (x+5)}\,d\theta \\ &=\frac {5^3}{2}\frac {6}{(x+5)^4}\int _0^\infty f_{\Gam (4,x+5)}(\theta )\,d\theta \\ &=\frac {375}{(x+5)^4} \end{align*} for \(x>0\) and zero otherwise.
-
(c) Using independence, the p.d.f. of the model family now becomes
\[f_{M_{\theta }}(x)=\prod _{i=1}^n \theta e^{-\theta x_i}=\theta ^n e^{-\theta \sum _1^n x_i}.\]
Let us write \(z=\sum _1^n x_i\). From Theorem 3.1.2 we have
\(\seteqnumber{0}{C.}{2}\)\begin{align*} f_{\Theta |_{\{X=x\}}}(\theta ) &= \frac {1}{Z} f_{M_\theta }(x)f_{\Gamma (2,3)}(\theta ) \\ &= \frac {1}{Z}\frac {3^2}{\Gamma (2)} \theta ^n e^{-\theta z} \theta e^{-3\theta } \\ &= \frac {1}{Z'} \theta ^{n+1} e^{-\theta (3+z)} \end{align*} for \(\theta >0\) and zero otherwise. We recognize the \(\Gam (n+2,3+z)\) distribution.
-
-
3.3 We obtain:
-
-
(a) In order: Section 1.1, Section 1.2, Lemma 1.4.1, Lemma 1.5.1, equation (1.9), Lemma 1.6.1.
-
(b) The first part combines Definition 2.2.1 (discrete case) and Definition 3.1.1 (continuous case). The second part combines equations (2.4) and (3.2). The third part combines Theorems 2.4.1 and 3.1.2, as discussed at the end of Section 3.1. The fourth part combines equations (2.8) and (3.5).
-
-
3.5 In this solution we will keep track of the normalizing constants. If you prefer to write them as \(\frac {1}{Z}\) in the style of e.g. (3.7) and use Lemma 1.2.5 to recognize the distributions, or to use \(\propto \) as introduced in Chapter 4, that is fine – but it is difficult to make that approach work for the predictive distribution in part (b)!
In this question we need to be very careful with the limits of integrals. The \(\Unif ([0,\theta ])\) p.d.f. is zero outside of \([0,\theta ]\) and the \(\Pareto (a,b)\) p.d.f. is zero outside of \((b,\infty )\). This matters particularly for the integrals in part (b).
-
(a) From Theorem 3.1.2 the posterior distribution has p.d.f.
\(\seteqnumber{0}{C.}{2}\)\begin{align*} f_{\Theta |_{\{X=5\}}}(\theta ) &= \frac {1}{\int _\R f_{\Unif ([0,t])}(5) f_{\Pareto (3,1)}(t)\, dt}f_{\Unif ([0,\theta ])}(\tfrac 12) f_{\Pareto (1,3)}(\theta ) \\ &=\frac {1}{\int _1^\infty \frac {1}{t}3t^{-4}\,dt} \frac {1}{\theta }3\theta ^{-4} \\ &=\frac {1}{\int _1^\infty 3t^{-5}\,dt} 3\theta ^{-5} \\ &=\frac {1}{3/4}\theta ^{-5} \\ &=4\theta ^{-5} \end{align*} for \(\theta >1\) and zero otherwise. We recognize the p.d.f. of the \(\Pareto (4,1)\) distribution. Note that to deduce the second line we used \(f_{\Unif ([0,\theta ])}(\tfrac 12)=\frac {1}{\theta }\), which was true because \(\frac 12<\theta \).
-
(b) From Theorem 3.1.2 the posterior distribution has p.d.f.
\(\seteqnumber{0}{C.}{2}\)\begin{align*} f_{\Theta |_{\{X=5\}}}(\theta ) &= \frac {1}{\int _\R f_{\Unif ([0,t])}(5) f_{\Pareto (1,3)}(t)\, dt}f_{\Unif ([0,\theta ])}(5) f_{\Pareto (3,1)}(\theta ) \\ &=\frac {1}{\int _1^\infty \1_{\{5\leq t\}}\frac {1}{t}3t^{-4}\,dt} \1_{\{5\leq \theta \}}\frac {1}{\theta }3\theta ^{-4} \\ &=\frac {1}{\int _5^\infty 3t^{-5}\,dt} \1_{\{5\leq \theta \}}3\theta ^{-5} \\ &=\frac {1}{3\frac {5^{-4}}{4}}\1_{\{5\leq \theta \}}\theta ^{-5} \\ &=\1_{\{5\leq \theta \}}5^44\theta ^{-5} \end{align*} We recognize the p.d.f. of the \(\Pareto (4,5)\) distribution.
From (3.5) the predictive distribution has p.d.f. given by
\(\seteqnumber{0}{C.}{2}\)\begin{align*} f_{X'}(x) &=\int _5^\infty f_{\Unif ([0,\theta ])}(x)f_{\Pareto (4,5)}(\theta )\,d\theta \\ &= \begin{cases} \int _x^\infty \frac {1}{\theta } 5^4 4\theta ^{-5}\,d\theta & \text { for }x>5 \\ \int _5^\infty \frac {1}{\theta } 5^4 4\theta ^{-5}\,d\theta & \text { for }x\in [0,5] \end {cases} \\ &= \begin{cases} \int _x^\infty \1_{x\leq \theta }5^4 4\theta ^{-6}\,d\theta & \text { for }x>5 \\ \int _5^\infty 5^4 4\theta ^{-6}\,d\theta & \text { for }x\in [0,5] \end {cases} \\ &= \begin{cases} 5^4 4[\frac {\theta ^{-5}}{-5}]_x^\infty & \text { for }x>5 \\ 5^4 4[\frac {\theta ^{-5}}{-5}]_5^\infty & \text { for }x\in [0,5] \end {cases} \\ &= \begin{cases} 5^4 4\frac 15x^{-5} & \text { for }x>5 \\ 5^4 4\frac 155^{-5} & \text { for }x\in [0,5] \end {cases} \\ &= \begin{cases} 5^3 4 x^{-5} & \text { for }x>5 \\ \frac {4}{5^2} & \text { for }x\in [0,5] \end {cases} \end{align*} for \(x\geq 0\) and zero otherwise.
-
-
3.6 Noting that \(\P [\Theta \in A]>0]\), we will use Lemma 1.5.1. For \(B\sw R_X\) we have
\(\seteqnumber{0}{C.}{2}\)\begin{align*} \P [X|_{\{\Theta \in A\}}\in B] &=\frac {\P [X\in B, \Theta \in A]}{\P [\Theta \in A]} =\frac {1}{\P [\Theta \in A]}\int _B\int _A f_{M_\theta }(x)f_\Theta (\theta )\,d\theta \,dx\\ &=\int _B\int _A f_{M_\theta }(x)f_{\Theta |_{\{\Theta \in A\}}}(\theta )\,d\theta \,dx. \end{align*} To deduce the last line above we use Exercise 1.8. It follows from Definition 1.1.1 that \(X|_{\{\Theta \in A\}}\) is a continuous random variable with p.d.f.
\[f_{X|_{\{\Theta \in A\}}}(x)=\int _A f_{M_\theta }(x)f_{\Theta |_{\{\Theta \in A\}}}(\theta )\,d\theta .\]
-
-
(a) We have
\[\int _\R f_{M'_\theta }(x)\,dx =\int _\R \int _\R f_{M_\theta }(x-y)\kappa (y)\,dy\,dx =\int _\R \kappa (y)\l (\int _\R f_{M_\theta }(x-y)\,dx\r )\,dy =\int _\R \kappa (y)\,dy =1.\]
Here we used that \(f_{M_\theta }\) is a p.d.f. which integrates to \(1\), and also our assumption that \(\kappa \) integrates to \(1\).
-
(b) By Theorem 3.1.2 we have \(f_{\Theta |_{\{X=x\}}}(\theta )=\frac {1}{Z}f_{M_\theta }(x)f_\Theta (\theta )\) and also that
\(\seteqnumber{0}{C.}{2}\)\begin{align*} f_{\Theta |_{\{X'=x\}}}(\theta ) = \frac {1}{Z'} f_{M'_\theta }(x) f_\Theta (\theta ) = \frac {1}{Z'} \int _\R f_{M_\theta }(x-y)\kappa (y)f_\Theta (\theta )\, dy = \frac {Z}{Z'} \int _\R f_{\Theta |_{\{X=x-y\}}}(\theta )\kappa (y)\,dy \end{align*} as required.
-
(c) In the case where \(\kappa (x)\) is the p.d.f. of \(\Normal (0,1)\), the convolution applied to Model 1 is equivalent to adding a \(\Normal (0,1)\) random variable to the data, which gives Model 2. That is, \(X'\eqd X+\Normal (0,1)\). Model 2 is therefore a version of Model 1 that is designed handle (additional) noise.
It helps to visualize things, which is left for you here: the effect of convolution on the probability density functions is to smooth them i.e. to spread out high peaks into lower and wider regions. Equation (3.10) says that the posterior density of \((X',\Theta )\) can be obtained by taking the posterior density of \((X,\Theta )\) and smoothing it in this way (with respect to the \(x\) coordinate).
-
Chapter 4
-
-
(a)
-
(i) The posterior is
\[\Normal \l (\frac {\frac {1}{4}(14.08)+\frac {0}{1}}{\frac {3}{4}+\frac {1}{1}},\frac {1}{\frac {3}{4}+\frac {1}{1}}\r ) \eqd \Normal (2.01,0.76^2)\]
where we have rounded the parameters to two decimal places.
-
(ii) The p.d.f. of the sampling distribution is
\[f_X(x)=\int _\R f_{\Normal (\theta ,2)}(x)f_{\Normal (0,1)}(\theta )\,d\theta .\]
The p.d.f. of the posterior distribution is
\[f_{X'}(x)=\int _\R f_{\Normal (\theta ,2)}(x)f_{\Normal (2.01,0.76^2)}(\theta )\,d\theta .\]
-
-
(b) See 2_dist_sketching_solution.ipynb and 2_dist_sketching_solution.Rmd.
-
-
4.2 From Theorem 2.4.1 we have
\(\seteqnumber{0}{C.}{2}\)\begin{align*} f_{\Theta |_{\{X=x\}}}(\theta ) & \propto \P [\Geo (\theta )^{\otimes n}=x]f_{\Beta (\alpha ,\beta )}(\theta ) \\ & \propto \l (\prod _{i=1}^n \theta (1-\theta )^{x_i}\r ) \frac {1}{\mc {B}(\alpha ,\beta )}\theta ^{\alpha -1}(1-\theta )^{\beta -1} \\ & \propto \theta ^n(1-\theta )^{\sum _1^n x_i}\theta ^{\alpha -1}(1-\theta )^{\beta -1} \\ & \propto \theta ^{\alpha +n-1}(1-\theta )^{\beta +\sum _1^nx_i-1} \end{align*} for \(\theta \in [0,1]\) and zero otherwise. Using Lemma 1.2.5, we recognize the \(\Beta (\alpha +n, \beta +\sum _1^n x_i)\) distribution, as required.
-
4.3 From Theorem 2.4.1 we have
\(\seteqnumber{0}{C.}{2}\)\begin{align*} f_{\Theta |_{\{X=x\}}}(\theta ) & \propto \P [\Poisson (\theta )^{\otimes n}=x]f_{\Gam (\alpha ,\beta )}(\theta ) \\ & \propto \l (\prod _{i=1}^n\frac {\theta ^{x_i} e^{-\theta }}{x_i!}\r ) \frac {\beta ^\alpha }{\Gamma (\alpha )}\theta ^{\alpha -1}e^{-\beta \theta } \\ & \propto \theta ^{\sum _1^n x_i} e^{-n\theta }\theta ^{\alpha -1}e^{-\beta \theta } \\ & \propto \theta ^{\alpha +\sum _1^n x_i-1}e^{-\theta (\beta +n)} \end{align*} for \(\theta >0\) and zero otherwise. Using Lemma 1.2.5, we recognize the \(\Gam (\alpha +\sum _1^n x_i, \beta +n)\) distribution, as required.
-
4.4 From Theorem 3.1.2 we have
\(\seteqnumber{0}{C.}{2}\)\begin{align*} f_{\Theta |_{\{X=x\}}}(\tau ) & \propto f_{\Normal (\mu ,\frac {1}{\tau })^{\otimes n}}(x) f_{\Gam (\alpha ,\beta )}(\tau ) \\ & \propto \l (\prod _{i=1}^n\frac {\sqrt {\tau }}{\sqrt {2\pi }}e^{-\frac {\tau (x_i-\mu )^2}{2}}\r ) \frac {\beta ^\alpha }{\Gamma (\alpha )}\tau ^{\alpha -1}e^{-\beta \tau } \\ & \propto \tau ^{\frac {n}{2}}\exp \l (-\frac {\tau }{2}\sum _1^n(x_i-\mu )^2\r )\tau ^{\alpha -1}e^{-\beta \tau } \\ & \propto \tau ^{\alpha +\frac {n}{2}-1}\exp \l [-\tau \l (\beta +\frac 12\sum _1^n(x_i-\mu )^2\r )\r ]. \end{align*} Using Lemma 1.2.5, we recognize the \(\Gam (\alpha +\frac {n}{2}, \beta +\frac 12\sum _1^n(x_i-\mu )^2)\) distribution, as required.
-
4.5 We obtain
-
-
(a) The posterior is \(N(2.013, 0.36)\).
-
(b) Writing the code is left for you. The result will be the same as in part (a).
-
(c) We have seen that the Bayesian updates here can be done all at once, or piece by piece, and will give the same results. Checking the formulae for the conjugate priors, in every other case covered in this chapter it is obvious that this will be the case – only in Lemma 4.2.2 are the update formulae complicated enough that it is not obvious from the formulae.
In fact, this principle holds with or without conjugate pairs, as we will see in Exercise 6.7.
-
-
4.7 From Theorem 3.1.2 we have
\(\seteqnumber{0}{C.}{2}\)\begin{align*} f_{\Theta |_{\{X=x\}}}(\theta ) & \propto f_{\Weibull (k,\theta )^{\otimes n}}(x) f_{\Gam (a,b)}(\theta ) \\ & \propto \l (\prod _{i=1}^n \theta k(x_i)^{k-1}e^{-\theta x_i^k}\r ) \frac {b^a}{\Gamma (a)} \theta ^{a-1}e^{-b\theta } \\ & \propto \theta ^n e^{-\theta \sum _1^n x_i^k}\theta ^{a-1}e^{-b\theta } \\ & \propto \theta ^{a+n-1}e^{-\theta (b+\sum _1^n x_i^k)}. \end{align*} Using Lemma 1.2.5, we recognize the \(\Gam (a+n, b+\sum _1^n x_i^k)\) distribution, as required.
-
4.8 Omitted.
-
-
(a) Taking \(C=1\) in Definition 4.1.1 gives \(f\propto f\).
-
(b) If \(f(x)=Cg(x)\) then \(g(x)=\frac {1}{C}f(x)\). Note that Definition 4.1.1 gives \(C>0\), so \(\frac {1}{C}>0\).
-
(c) If \(f(x)=Cg(x)\) and \(g(x)=C'h(x)\) then \(f(x)=CC'h(x)\). Note that Definition 4.1.1 gives \(C,C'>0\), so \(CC'>0\).
-
Chapter 5
-
5.1 The data from Census 2021 is as follows.
Age band Population Proportion (2dp) 10+ 60096227 0.89 20+ 52089688 0.77 30+ 43661735 0.65 40+ 34458842 0.51 50+ 26028478 0.39 60+ 16814195 0.25 70+ 9316631 0.14 80+ 3399106 0.05 90+ 609904 0.01 The total population was 67596281.
The point of this question that you will (probably) find it more difficult to give accurate estimates for events that have smaller probabilities.
-
5.2 This is up to you!
-
5.3 For the model family \((M_\lambda )_{\lambda \in (0,\infty )}\) in which \(M_\lambda \sim \Poisson (\lambda )\) we have
\[L_{M_\lambda }(x)= \begin {cases} \dfrac {\lambda ^x e^{-\lambda }}{x!} & \text { for }\lambda >0 \\ 0 & \text { otherwise} \end {cases} \]
where \(x\in \{0,1,\ldots \}\). Hence \(\frac {d}{d\lambda }\log (L_{M_\lambda }(x))=\frac {d}{d\lambda } (x\log (\lambda )-\lambda -x!)=\frac {x}{\lambda }-1=\frac {x-\lambda }{\lambda }\). For \(\lambda >0\), the density function of the Jeffrey’s prior is given by
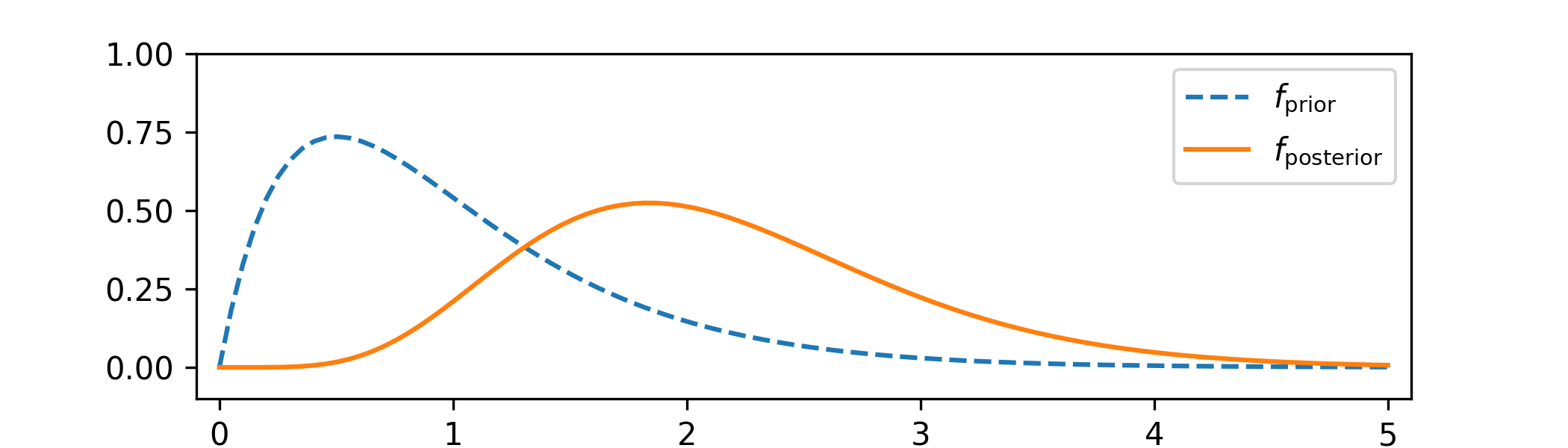
\(\seteqnumber{0}{C.}{2}\)\begin{align*} f_\Lambda (\lambda ) &\propto \E \l [\l (\frac {d}{d\theta }\log (L_{M_{\theta }}(X))\r )^2\r ]^{1/2} \\ &\propto \E \l [\l (\frac {X-\lambda }{\lambda }\r )^2\r ]^{1/2} \\ &\propto \frac {1}{\lambda }\E \l [\l (X-\lambda \r )^2\r ]^{1/2} \\ &\propto \frac {1}{\lambda }\var (X)^{1/2} \\ &\propto \frac {1}{\lambda }\lambda ^{1/2} \\ &\propto \frac {1}{\lambda ^{1/2}}. \end{align*} Noting that \(\int _0^\infty \frac {1}{\lambda ^{1/2}}\,d\lambda =\infty \), this is an improper prior.
-
5.4 Our model here is \(M_\lambda =\Poisson (\lambda )^{\otimes 12}\). From Theorem 2.4.1 we have
\(\seteqnumber{0}{C.}{2}\)\begin{align*} f_{\Lambda |_{\{X=x\}}}(x) &\propto \l (\prod _{i=1}^12\frac {\lambda ^{x_i} e^{-\lambda }}{x_i!}\r )\frac {1}{\sqrt {\lambda }} \\ &\propto \lambda ^{\sum _1^{12} x_i - \frac 12}e^{-12\lambda }. \end{align*} Using Lemma 1.2.5 we recognize the \(\Gam (\frac 12+\sum _1^{n} x_i, n)\) distribution with \(n=12\). This is a proper distribution for all values of \(x\), which answers part (b). For part (a) we have \(\sum _1^{12}x_i=5\), so we obtain \(\Lambda |_{\{X=x\}}\sim \Gam (\frac {11}{2},12)\). A sketch looks like
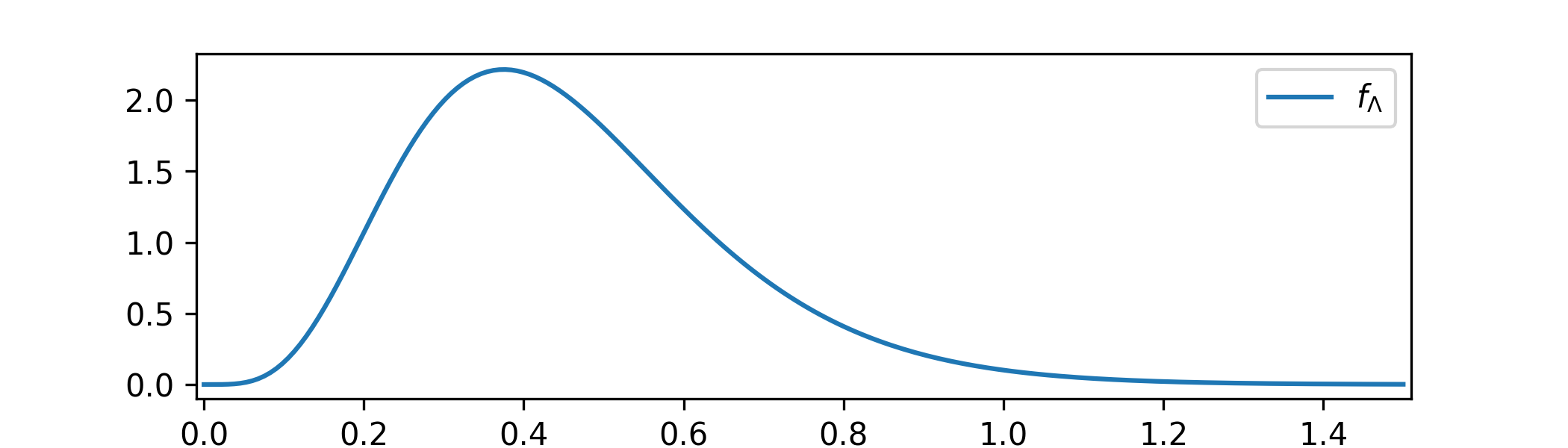
-
-
(a) From Theorem 3.1.2 we have
\(\seteqnumber{0}{C.}{2}\)\begin{align*} f_{\Theta |_{\{X=x\}}}(\theta ) \propto f_{\Unif (0,\theta )}(x)f_{\Exp (1)}(\theta ) \propto \begin{cases} \frac {1}{\theta } e^{-\theta x} & \text { for }\theta >x>0, \\ 0 & \text { otherwise,} \end {cases} \propto \begin{cases} e^{-\theta x} & \text { for }\theta >x>0,\\ 0 & \text { otherwise.} \end {cases} \end{align*} The distribution \(\Unif (0,\theta )\) only generates values in \((0,\theta )\), so in order to generate the data \(x\) it must have \(x\in (0,\theta )\). For this reason our posterior places zero weight on \(\theta <x\). (The boundary \(x=\theta \) has probability zero, so it does not matter what happens there.)
-
(b) The posterior is not well defined in this case. Formally the condition \(x\in R\) of Theorem 3.1.2 is not satisfied. From a more practical point of view, we have failed to account for Cromwell’s rule. Our prior density is zero outside of \(\theta \in (1,2)\) but our model makes sense for all \(\theta >0\), and to generate the data \(x=3\) we would need to have \(\theta >3\).
-
-
5.6 We argue by contradiction: suppose such a \(U\) does exist. Take \(c=1\) and \([a,b]=[n,n+1]\) and we obtain that \(\P [U\in [n,n+1]]=\P [U\in [n+1,n+2]]\). By a trivial induction we have \(\P [U\in [0,1]]=\P [U\in [1,2]]=\P [U\in [2,3]]=\ldots \), but then
\[1=\P [U\in [0,\infty )]=\sum _{n=0}^\infty \P [U\in [n,n+1]]=\sum _{n=0}^\infty \P [U\in [0,1]].\]
This a contradiction: the right hand side is either \(0\) (if \(\P [U\in [0,1]]=0\)) or equal to \(\infty \) (if \(\P [U\in [0,1]]>0)\).
-
5.7 Bob chooses his prior to be \(h(\Theta )\), where \(\Theta \) is Alice’s prior with p.d.f. \(f_1\). As \(h\) is strictly monotone increasing and differentiable, this means that Bob’s prior has p.d.f.
\[f_2(\theta )=\frac {dh^{-1}}{d\theta }f_1\l (h^{-1}(\theta )\r ).\]
Take Alice’s sampling distribution and substitute \(\theta =h(\lambda )\) to obtain
\(\seteqnumber{0}{C.}{2}\)\begin{align*} f_{X_1}(x) &=\int _\Pi f_{M_\theta }(x)f_1(\theta )\,d\theta \\ &=\int _\Pi f_{M_{h(\lambda )}}(x)f_1\l (h^{-1}(\lambda )\r )\frac {dh^{-1}}{d\lambda }\,d\lambda \\ &=\int _\Pi f_{M_{h(\lambda )}}(x)f_2(\lambda )\,d\lambda \\ &=f_{X_2}(x) \end{align*} as required.
-
5.8 By independence we have \(L_{M_\theta ^{\otimes n}}(x)=\prod _{i=1}^n L_{M_\theta }(x_i)\), hence \(\log L_{M_\theta ^{\otimes n}}(x)=\sum _1^n \log L_{M_\theta }(x_i)\). Taking \(X=(X_i)\sim M_\theta ^{\otimes n}\) so that \(X_i\sim M_\theta \) for all \(i\), we have
\(\seteqnumber{0}{C.}{2}\)\begin{align*} \E \l [-\frac {d}{d\theta ^2} \log L_{M_\theta ^{\otimes n}}(X)\r ] &= \E \l [-\frac {d}{d\theta ^2} \sum _1^n \log L_{M_\theta }(X_i)\r ] \\ &= \sum _{i=1}^n \E \l [-\frac {d}{d\theta ^2} \log L_{M_\theta }(X_i)\r ]. \end{align*} Hence by (5.3)
\(\seteqnumber{0}{C.}{2}\)\begin{align*} f_{M_\theta ^{\otimes n}}(\theta ) \propto \sum _{i=1}^n f_{M_\theta }(\theta ) \propto n f_{M_\theta }(\theta ) \propto f_{M_\theta }(\theta ) \end{align*} as required.
Chapter 6
-
6.1 We have \(f_{\Gam (\alpha ,\beta )}(x)\propto x^{\alpha -1}e^{-\beta x}\) when \(x>0\) and zero otherwise. Differentiating, we have
\(\seteqnumber{0}{C.}{2}\)\begin{equation*} \label {eq:gamma_pdf_diff} (\alpha -1)x^{\alpha -2}e^{-\beta x}+x^{\alpha -1}(-\beta )e^{-\beta x}=x^{\alpha -2}e^{-\beta x}(\alpha -1-\beta x). \end{equation*}
This takes the value zero when, and only when, \(\alpha -1-\beta x=0\), which gives \(x=\frac {\alpha -1}{\beta }\). If \(\alpha \geq 1\) then this value is within the range of \(\Gam (\alpha ,\beta )\). Since \(f_{\Gam (\alpha ,\beta )}(0)=0\) and \(\lim _{x\to \infty }f_{\Gam (\alpha ,\beta )}(x)=0\), and there is only one turning point, that turning point must be a global maximum. Hence it is also the mode, given by \(\frac {\alpha -1}{\beta }\).
If \(\alpha \in (0,1)\) then from (C) we have that \(f_{\Gam (\alpha ,\beta )}(x)\) has negative derivative for all \(x>0\). Hence it is a decreasing function, and the maximum will occur at \(x=0\). So the mode is zero, when \(\alpha \in (0,1)\).
-
-
(a) Lemma 1.6.1.
-
(b) Lemma 4.1.5.
-
(c) If \(\lambda \sim \Gam (\alpha ,\beta )\) and \(x|\lambda \sim \Exp (\lambda )^{\otimes n}\) then \(\lambda |x\sim \Beta (\alpha +n,\beta +\sum _1^n x_i)\).
-
(d) If \((\mu ,\tau )\sim \NGam (m,p,a,b)\) then \(\tau \sim \Gam (a,b)\) and \(\mu |\tau \sim \Normal (m,\frac {1}{p\tau })\).
-
-
-
(a) If \(X\sim N(0,1)\) then \(X|_{\{X>0\}}\eqd |X|\). This is the result of Exercise 1.7, which is closely related to Example 1.4.3.
-
(b) If \(X\) and \(Y\) are independent random variables then \(X|_{\{Y=y\}}\eqd X\). This is true if the conditioning is well defined, as discussed (in more general terms) at the start of Section 1.5.
-
-
-
(a) We have \(f_{\NBin (m,\theta )}(x_i)\propto \theta ^m(1-\theta )^{x_i}\), for \(x_i\in \{0,1,\ldots ,\}\). Hence
\[f(x|\theta )=f_{\NBin (m,\theta )^{\otimes n}}(x)\propto \prod _{i=1}^n\theta ^m(1-\theta )^{x_i} \propto \theta ^{mn}(1-\theta )^{\sum _1^n x_i}.\]
-
(b) From Theorem 3.1.2 we have
\(\seteqnumber{0}{C.}{2}\)\begin{align*} f(\theta |x) &\propto f_{\NBin (m,\theta )^{\otimes n}}(x)f_{\Beta (\alpha ,\beta )}(\theta ) \\ &\propto \theta ^{mn}(1-\theta )^{\sum _1^n x_i}\theta ^{\alpha -1}(1-\theta )^{\beta -1} \\ &\propto \theta ^{\alpha +mn-1}(1-\theta )^{\beta +\sum _1^n x_i-1}. \end{align*} By Lemma 1.2.5 we recognize \(\theta |x\sim \Beta (\alpha ^*,\beta ^*)\) with \(\alpha ^*=\alpha +mn\) and \(\beta ^*=\beta +\sum _1^n x_i\).
-
(c)
-
(i) The reference prior is given by
\(\seteqnumber{0}{C.}{2}\)\begin{align*} f(\theta ) &\propto \E \l [-\frac {d^2}{d\theta ^2}\log L_{\NBin (m,\theta )}(X)\r ]^{1/2} \\ &\propto \E \l [-\frac {d^2}{d\theta ^2}\log \l (\theta ^{mn}(1-\theta )^{\sum _1^n X_i}\r )\r ]^{1/2} \\ &\propto \E \l [-\frac {d^2}{d\theta ^2}\l (mn\log \theta + \sum _1^n X_i\log (1-\theta )\r )\r ]^{1/2} \\ &\propto \E \l [\frac {mn}{\theta ^2} + \frac {\sum _1^n X_i}{(1-\theta )^2}\r ]^{1/2} \\ &\propto \l (\frac {mn}{\theta ^2} + \frac {mn(1-\theta )}{\theta }\frac {1}{(1-\theta )^2}\r )^{1/2} \end{align*} where we use that \(X_i\sim \NBin (m,\theta )\) has mean \(\frac {m(1-\theta )}{\theta }\). Hence
\[f(\theta ) \propto \l (\frac {mn(1-\theta )+mn\theta }{\theta ^2(1-\theta )}\r )^{1/2} \propto \theta ^{-1}(1-\theta )^{-1/2}. \]
-
(ii) \(f(\theta )\propto \theta ^{-1}(1-\theta )^{-1/2}\) not define a proper distribution. To see this,
\[\int _0^\frac 12 \theta ^{-1}(1-\theta )^{-1/2}\,d\theta \geq \int _0^\frac 12 \theta ^{-1}(1/2)^{-1/2}\,d\theta =\infty .\]
-
(iii) From Theorem 3.1.2 the prior is given by
\(\seteqnumber{0}{C.}{2}\)\begin{align*} f(\theta |x) &\propto \theta ^{mn}(1-\theta )^{\sum _1^n x_i}\theta ^{-1}(1-\theta )^{-1/2} \\ &\propto \theta ^{mn-1}(1-\theta )^{\sum _1^n x_i-\frac 12}. \end{align*} Using Lemma 1.2.5 we recognize \(\theta |x\sim \Beta (mn, \sum _1^n x_i+\frac 12).\)
-
-
-
-
(a) By Theorem 3.1.2 the posterior distribution has p.d.f.
\(\seteqnumber{0}{C.}{2}\)\begin{align*} f(\mu ,\tau |x) &\propto \l (\prod _{i=1}^n f_{\N (\mu ,\frac {1}{\tau })}(x_i)\r )\frac {1}{\tau } \\ &\propto \l (\prod _{i=1}^n \frac {1}{\sqrt {\tau }}e^{-\frac 12\tau (x_i-\mu )^2}\r )\frac {1}{\tau } \\ &\propto \tau ^{\frac {n}{2}-1}\exp \l (-\frac {\tau }{2}\sum _1^n(x_i-\mu )^2\r ) \end{align*} where \(s^2=\frac {1}{n}\sum _1^n(x_i-\mu )^2\).
-
(b) To find the marginal distribution of \(\tau \) we must integrate over \(\mu \), giving
\(\seteqnumber{0}{C.}{2}\)\begin{align*} f(\tau |x) &\propto \int _\R \tau ^{\frac {n}{2}-1}\exp \l (-\frac {\tau }{2}\sum _1^n(x_i-\mu )^2\r )\,d\mu \\ &\propto \int _\R \tau ^{\frac {n}{2}-1}\exp \l (-\frac {\tau }{2}\l (ns^2 + (\bar {x}-\mu )^2\r )\r )\,d\mu \\ &\propto \tau ^{\frac {n}{2}-1-\frac 12}e^{-\frac 12\tau n s^2}\int _\R \tau ^{1/2}\exp \l (-\frac {\tau }{2}(\bar {x}-\mu )^2\r )\,d\mu \\ &\propto \tau ^{\frac {n-1}{2}-1}e^{-\frac 12\tau n s^2}\int _\R f_{\Normal (\bar {x},\frac {1}{\tau })(\mu )}\,d\mu \\ &\propto \tau ^{\frac {n-1}{2}-1}e^{-\frac 12\tau n s^2}. \end{align*} Using Lemma 1.2.5 for \(n\geq 2\) we recognize \(\tau |x\sim \Gam (a^*,b^*)\) where \(a^*=\frac {n-1}{2}\) and \(b^*=\frac 12ns^2\). If \(n=1\) then this does not correspond to a Gamma distribution, because in this case \(a^*=0\) and the Gamma distribution requires parameters in \((0,\infty )\).
We have
\(\seteqnumber{0}{C.}{2}\)\begin{align*} \int _0^\infty \int _{\R } f(\mu ,\tau |x)\,d\mu \,d\tau &= \int _0^\infty f(\tau |x)\,d\tau \\ &\propto \int _0^\infty f(\tau |x)\,d\tau , \end{align*} which is finite if \(n\geq 2\) because the Gamma distribution is proper. If \(n=1\) then we have
\(\seteqnumber{0}{C.}{2}\)\begin{equation} \label {eq:improper_tau_gamma} \int _0^\infty \int _{\R } f(\mu ,\tau |x)\,d\mu \,d\tau =\int _0^\infty \tau ^{-1}e^{-\frac 12\tau s^2}\,d\tau \geq e^{-\frac 12 s^n}\int _0^1 \frac {1}{\tau }\,d\tau =\infty . \end{equation}
Here we use that \(e^{-\frac 12\tau s^2}\geq e^{-\frac 12 s^n}\) for \(\tau \in [0,1]\). Hence \(f(\mu ,\tau |x)\) defines an improper distribution when \(n=1\).
-
-
-
(a) We have \(f_{\Theta _i}(\theta )\geq 0\) and \(\alpha ,\beta \geq 0\) so also \(f_{\Theta }(\theta )\geq 0\). Also,
\[\int _\R f_{\Theta }(\theta )\,d\theta =\alpha \int _\R f_{\Theta _1}(\theta )\,d\theta +\beta \int _\R f_{\Theta _2}(\theta )\,d\theta =\alpha (1)+\beta (1)=1.\]
-
(b) By Theorem 3.1.2 we have
\(\seteqnumber{0}{C.}{3}\)\begin{align*} f_{\Theta |_{\{X=x}\}}(\theta ) &= \frac {f_{M_\theta }(x)f_{\Theta }(\theta )}{\int _{\R ^n}f_{M_\theta }(x)f_{\Theta }(\theta )\,dx} \\ &=\frac {\alpha f_{M_\theta }(x)f_{\Theta _1}(\theta ) + \beta f_{M_\theta }(x)f_{\Theta _2}(\theta )} {\int _{\R ^n}f_{M_\theta }(x)f_{\Theta _1}(\theta )\,dx+\int _{\R ^n}f_{M_\theta }(x)f_{\Theta _2}(\theta )\,dx} \\ &=\alpha ' f_{\Theta _1|_{\{X_1=x\}}}(\theta )+\beta ' f_{\Theta _1|_{\{X_1=x\}}}(\theta ) \end{align*} where
\(\seteqnumber{0}{C.}{3}\)\begin{align*} \alpha ' &= \frac {\alpha \int _{\R ^n}f_{M_\theta }(x)f_{\Theta _1}(\theta )\,d\theta } {\alpha \int _{\R ^n}f_{M_\theta }(x)f_{\Theta _1}(\theta )\,dx+\beta \int _{\R ^n}f_{M_\theta }(x)f_{\Theta _2}(\theta )\,dx} =\frac {\alpha Z_1}{\alpha Z_1+\beta Z_2} \\ \beta &= \frac {\beta \int _{\R ^n}f_{M_\theta }(x)f_{\Theta _2}(\theta )\,d\theta } {\alpha \int _{\R ^n}f_{M_\theta }(x)f_{\Theta _1}(\theta )\,dx+\beta \int _{\R ^n}f_{M_\theta }(x)f_{\Theta _2}(\theta )\,dx} =\frac {\beta Z_2}{\alpha Z_1+\beta Z_2} \end{align*} where \(Z_1\) and \(Z_2\) are the normalizing constants (from Theorem 3.1.2) for \(f_{\Theta _1|_{\{X_1=x\}}}\) and \(f_{\Theta _2|_{\{X_1=x\}}}\) respectively, as required.
-
(c) To cover discrete Bayesian models, instead of probability density functions \(f_{M_\theta }\) in (b) we can use probability mass functions \(p_{M_\theta }\). We then need Theorem 2.4.1 in place of Theorem 3.1.2, but the argument is otherwise the same.
We could also cover both cases at once by using likelihood functions and (6.2).
-
-
-
(a)
-
(i) From the combined version of Bayes rule (6.2) we have
\[f_{\Theta |_{\{X=x\}}}(\theta ) \propto L_{M_\theta ^{\otimes n}}(x)f_{\Theta }(\theta ).\]
Applying (6.2) twice, we obtain
\(\seteqnumber{0}{C.}{3}\)\begin{align*} f_{\Theta |_{\{X_1=x(1)\}}}(\theta ) &\propto L_{M_\theta ^{\otimes n_1}}(x(1)) f_{\Theta }(\theta ) \\ f_{(\Theta |_{\{X_1=x(1)\}})|_{\{X_2=x(2)\}}}(\theta ) &\propto L_{M_\theta ^{\otimes n_2}}(x(2)) L_{M_\theta ^{\otimes n_1}}(x(1)) f_{\Theta }(\theta ) \end{align*} We note that by independence
\[L_{M_\theta ^{\otimes n_2}}(x(2)) L_{M_\theta ^{\otimes n_1}}(x(1)) =\l (\prod _{i=1}^{n_1}L_{M_\theta }(x_i)\r ) \l (\prod _{i=n_1+1}^{n_2}L_{M_\theta }(x_i)\r ) \\ =\l (\prod _{i=1}^{n_2}L_{M_\theta }(x_i)\r ) =L_{M_\theta ^{\otimes n}}(x). \]
Hence \(f_{(\Theta |_{\{X_1=x(1)\}})|_{\{X_2=x(2)\}}}(\theta )\propto f_{\Theta |_{\{X=x\}}}(\theta )\), which by Lemma 1.2.5 implies that \((\Theta |_{\{X_1=x(1)\}})|_{\{X_2=x(2)\}}\eqd \Theta |_{\{X=x\}}\) as required.
-
(ii) Applying a trivial induction to the result in part (a) we have shown that, in general for independent data, performing Bayesian updates in individual steps for each data point (or combinations of datapoints) will give the same results as performing one Bayesian update with all our data at once. This implies the result of Exercise 4.6.
-
-
(b) From Bayes rule we have
\(\seteqnumber{0}{C.}{3}\)\begin{align*} f(\theta |x) &\propto f(x|\theta ) f(\theta ) \\ f(\theta |x(1)) &\propto f(x(1)|\theta ) f(\theta ) \\ f(\theta |x(1),x(2)) &\propto f(x(2)|\theta ) f(x(1)|\theta ) f(\theta ). \end{align*} By independence (or more strictly, by conditional independence of \(x(1)\) and \(x(2)\) given \(\theta \)) we have
\[f(x|\theta )=f(x(1),x(2)|\theta ) \propto f(x(1)|\theta )f(x(2)|\theta )\]
hence \(f(\theta |x) \propto f(\theta |x(1),x(2))\). By Lemma 1.2.5 we have \(\theta |x\eqd \theta |x(1),x(2)\).
-
Chapter 7
-
7.1 \(f_X\) can be reasonably approximated by its mode. The median and mean would not be particularly bad choices, but the mode is best because the long right-hand tail (that does not contain much mass) will pull the median and mean slightly rightwards, away from the from region of highest density.
\(f_Y\) is tricky, because now the right hand tail contains substantial mass. It would be better not to approximate it with a point estimate, but if we had to do so then the median or mean would be reasonable choices, depending on the context. Alongside our point estimate, we should try to make sure the right-hand skew of the distribution is communicated in some way. The mode will be far below most of the mass of the distribution, so is a bad choice here.
There is no reasonable way to approximate \(f_Z\) with a point estimate. We could not capture the key feature of the distribution: that it has two approximately evenly sized peaks in different regions.
-
-
(a) We find numerically that the prior and posterior odds ratios are
\[ \frac {\P [\Beta (2,8)>0.2]}{\P [\Beta (2,8)\leq 0.2]}=0.77 \qquad \text { and }\qquad \frac {\P [\Beta (11,19)>0.2]}{\P [\Beta (11,19)\leq 0.2]}=49.75 \]
to two decimal places. The Bayes factor is \(64.30\).
-
(b) For \(x\in \{0,1,\ldots ,m\}\) and \(p\in [0,1]\) we have
\[L_{\Bin (m,p)^{\otimes n}}(x)\propto p^x(1-p)^{m-x}\]
so \(\log L_{\Bin (m,p)}(x)= x\log p + (m-x)\log (1-p)\). Hence
\[\frac {d^2}{dp^2} \log L_{\Bin (m,p)}(x)=\frac {-x}{p^2}+\frac {1-x}{(1-p)^2}.\]
Setting \(X\sim \Bin (m,p)\) and using (5.3), the reference prior has density
\(\seteqnumber{0}{C.}{3}\)\begin{align*} f(p) &\propto \E \l [\frac {X}{p^2}+\frac {m-X}{(1-p)^2}\r ]^{1/2} \\ &\propto \l (\frac {\E [X]}{p^2}+\frac {m-\E [X]}{(1-p)^2}\r )^{1/2} \\ &\propto \l (\frac {mp}{p^2}+\frac {m-mp}{(1-p)^2}\r )^{1/2} \\ &\propto \l (\frac {1}{p}+\frac {1}{1-p}\r )^{1/2} \\ &\propto \l (\frac {1}{p(1-p)}\r )^{1/2}. \end{align*} Using Lemma 1.2.5 we identify then \(\Beta (\frac 12,\frac 12)\) distribution.
We find numerically that the prior and posterior odds ratios are
\[ \frac {\P [\Beta (\frac 12,\frac 12)>0.2]}{\P [\Beta (\frac 12,\frac 12)\leq 0.2]}=2.39 \qquad \text { and }\qquad \frac {\P [\Beta (\frac 12+9,\frac 12+11)>0.2]}{\P [\Beta (\frac 12+9,\frac 12+11)\leq 0.2]}=191.15 \]
to two decimal places. The Bayes factor is \(80.05\).
The Bayes factor has not changed much, even though the odds ratios are quite different. For both choices of prior it suggests strong evidence for \(H_0\) over \(H_1\).
-
(c) The regulator will be interested by both sets of analysis. In particular, by the fact that both Bayes factors (using the informative prior elicited from the scientist and the uninformative reference prior) point towards the hypothesis \(\theta >0.2\), suggests that the analysis is robust i.e. is not overly sensitive to the particular methodology used.
This is a highly stylized example. Medical trials tend to be complex experiments with multiple subgroups, typically with outcomes that are not easily reducible to success vs. failure. The process of deciding what statistics will be reported is often done in negotiation with the regulator, before the trial begins.
-
-
-
(a) The reference density \(f(\lambda )\) is not proper, so we cannot calculate the probabilities that \(\lambda \in [0,2)\) or \(\lambda \in [2,\infty )\) with respect to this density. The prior odds are not well-defined in this situation.
-
(b) The data given has \(n=40\) and \(\sum _1^n x_i=109\). Hence the posterior is \(\lambda |x\sim \Gam (\frac 54+109,\frac 15+40)\eqd \Gam (110.25, 40.2)\). We find numerically that the prior and posterior odd ratios are
\[ \frac {\P [\Gam (\frac {5}{4},\frac {1}{5})\geq 2]}{\P [\Gam (\frac {5}{4},\frac {1}{5})<2]}=3.42 \qquad \text { and }\qquad \frac {\P [\Gam (110.25, 40.2)\geq 2]}{\P [\Gam (110.25, 40.2)<2]}=1093.84 \]
to two decimal places. The Bayes factor is \(319.75\).
We have (very) strong evidence for \(H_0\) over \(H_1\). A Poisson model is known to be reasonable, at least over large enough intervals of time, for large earthquakes. Assuming that we believe this model, we have strong evidence that Japan will, on average, experience two or more earthquakes of magnitude above \(7.5\) every year.
In case this sounds like unreasonably many earthquakes: earthquakes can occur deep underground, as well as offshore, and in such a case you may not hear much about them.
-
(c) For our new hypothesis \(H_0:\lambda \geq 3\), we find numerically that the prior and posterior odd ratios are
\[ \frac {\P [\Gam (\frac {5}{4},\frac {1}{5})\geq 3]}{\P [\Gam (\frac {5}{4},\frac {1}{5})<3]}=1.95 \qquad \text { and }\qquad \frac {\P [\Gam (110.25, 40.2)\geq 3]}{\P [\Gam (110.25, 40.2)<3]}=0.19 \]
to two decimal places. The Bayes factor is \(0.09\).
There is no evidence here to favour \(H_0\) over the opposite hypothesis \(H_1:\lambda <3\). In fact, swapping \(H_0\) and \(H_1\) will mean that the Bayes factor becomes \(1/B\), which in this case is \(1/0.09=10.14\), meaning that we have strong evidence to favour \(H_1\) over \(H_0\).
-
-
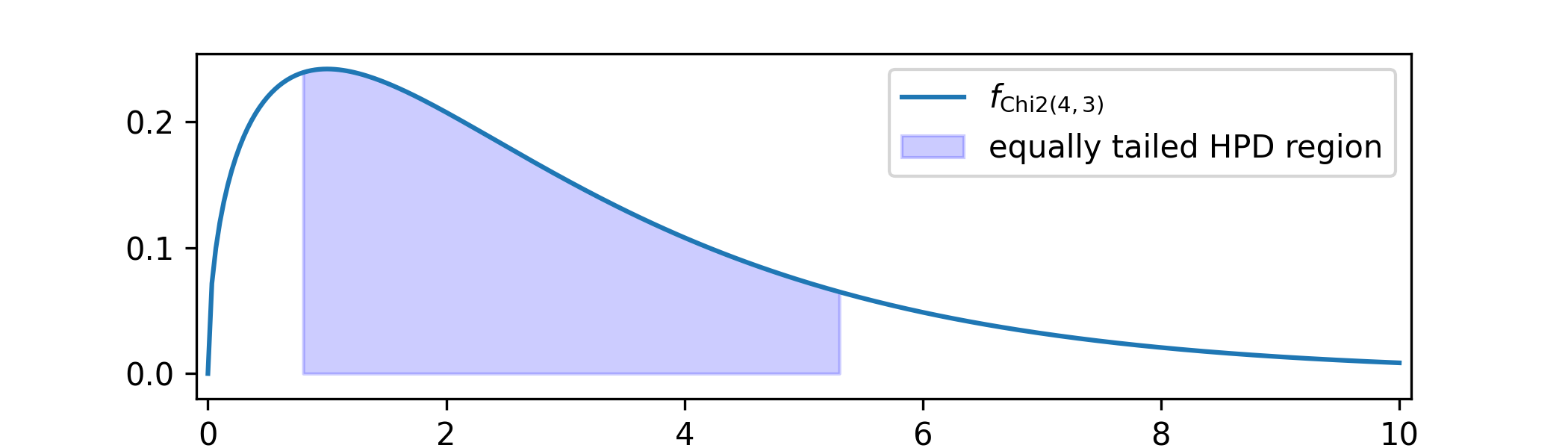
7.4 You should obtain \(a=0.80\) and \(b=5.32\) to two decimal places, and the following figure.
-
-
(a) I will spare you the details, but I have conducted an elicitation procedure on my wife who has (somewhat reluctantly) supplied us with the prior distribution \(\Exp (\frac {1}{1.7})\).
-
(b) The dataset has \(n=8\) and \(\sum _1^nx_i=18\). Hence the posterior distribution is \(\Gam (1+18,\frac {1}{1.7}+8)=\Gam (19, 8.59)\) with parameters to two decimal places.
-
(c) An equally tailed \(95\%\) HPD region is \([1.33,3.31]\), to two decimal places, and looks like
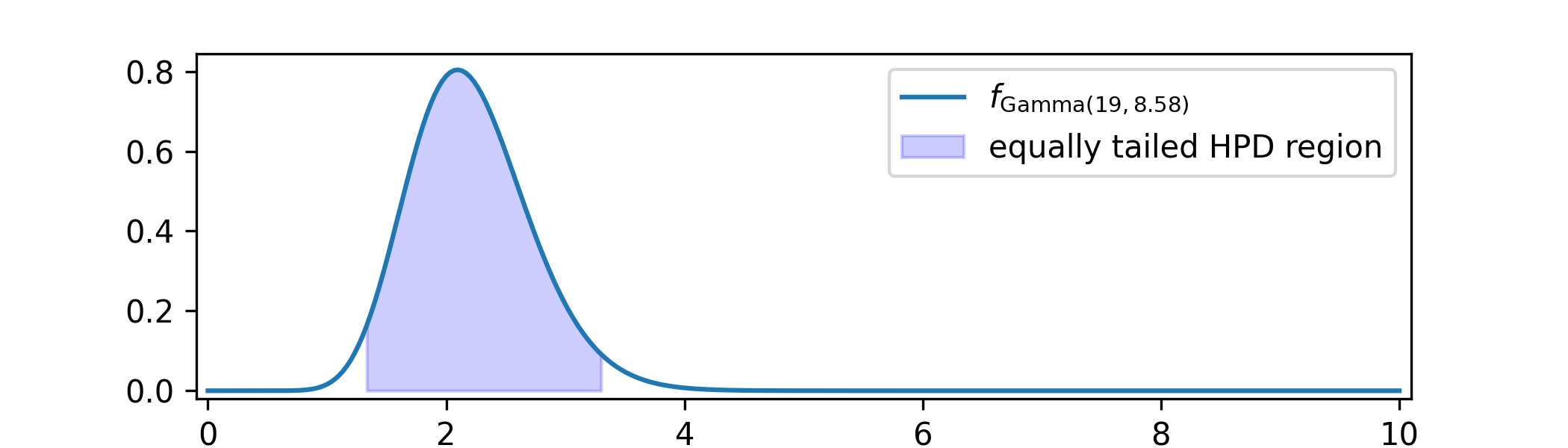
-
-
-
(a) From the dataset we have \(n=40\), \(\bar {x}=7.55\) and \(s^2=0.51\), to two decimal places. Hence \(t|x\sim \Studentt (39)\) with a \(95\%\) HPD region \([-2.02,2.02]\),
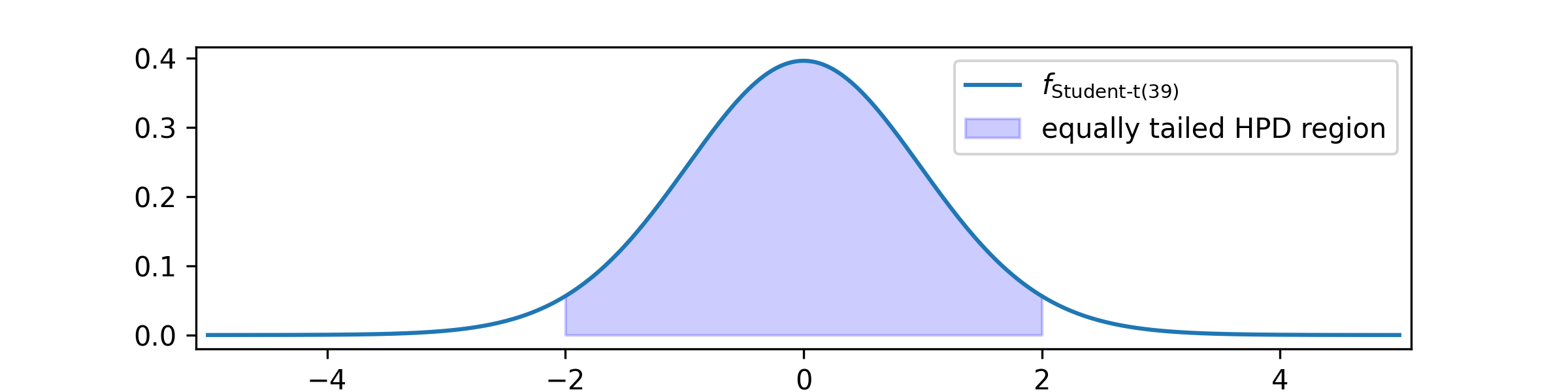
The relationship between \(\mu |x\) and \(t|x\) is that \(\mu |x=\bar {x}+(t|x)\frac {\sqrt {n}}{s}\). Note that the distribution of \(t|x\) is symmetric about \(0\), hence the distribution of \(\mu |x=\bar {x}+(t|x)\frac {\sqrt {n}}{s}\) will also be symmetric about its mean, and the mean of \(\mu |x\) will be \(\bar {x}\). An equally tailed \(95\%\) HPD region is given by \([\bar {x}-2.02\frac {\sqrt {n}}{s},\bar {x}+2.02\frac {\sqrt {n}}{s}]\). Putting in \(\bar {x}\), \(n\) and \(s\), and this comes out as \([7.33, 7.78]\) to two decimal places.
-
(b) The posterior density function is given by
\(\seteqnumber{0}{C.}{3}\)\begin{align*} f(\mu ,\phi ) &= \l (\prod _{i=1}^nf_{\Normal (\mu ,\phi )}(x_i)\r )\frac {1}{\phi } \\ &\propto \frac {1}{\phi ^{n/2+1}}\exp \l (-\frac {1}{2\phi }\sum _1^n(x_i-\mu )^2\r ) \\ &\propto \frac {1}{\phi ^{n/2+1}}\exp \l (-\frac {1}{2\phi }\l (ns^2+n(\bar {x}-\mu )^2\r )\r ) \end{align*} where we have used (4.10) and the notation of that identity, \(\bar {x}=\sum _1^n x_i\) and \(s^2=\frac {1}{n}\sum _1^n(x_i-\bar {x})^2\). Hence the marginal density \(f(\mu |x)\) satisfies
\(\seteqnumber{0}{C.}{3}\)\begin{align*} f(\mu |x) &\propto \int _0^\infty \frac {1}{\phi ^{n/2+1}}\exp \l (-\frac {1}{2\phi }\l (ns^2+n(\bar {x}-\mu )^2\r ))\r ) \,d\phi . \end{align*} To compute this integral we make the substitution \(\psi =\frac {1}{2\phi }(ns^2+n(\bar {x}-\mu )^2)\). We have \(\frac {d\psi }{d\phi }=\frac {-1}{2\phi ^2}(ns^2+n(\bar {x}-\mu )^2)\), and hence
\(\seteqnumber{0}{C.}{3}\)\begin{align*} f(\mu |x) &\propto \int _0^\infty \frac {1}{\phi ^{n/2+1}}e^{-\psi }\frac {2\phi ^2}{ns^2+n(\bar {x}-\mu )^2} \,d\psi \\ &\propto \frac {1}{\l (ns^2+n(\bar {x}-\mu )^2\r )^{n/2}}\int _0^\infty \psi ^{n/2-1}e^{-\psi }\,d\psi \\ &\propto \frac {1}{\l (ns^2+n(\bar {x}-\mu )^2\r )^{n/2}} \end{align*} where we use the fact that \(\int _0^\infty f_{\Gam (n/2,1)}(\psi )\,d\psi =1\). We lastly transform \(t=\frac {\mu -\bar {x}}{S/\sqrt {n}}\), to transform the probability density function of \(\mu |x\) into that of \(\tau |x\), giving
\(\seteqnumber{0}{C.}{3}\)\begin{align*} f(\tau |x) \propto f(\mu |x)\l |\frac {d\mu }{dt}\r | \\ \propto \l (ns^2+n\frac {S^2t^2}{n}\r )^{n/2}\\ \propto \l (1+\frac {t^2}{n-1}\r )^{-n/2} \end{align*} Note that \(\l |\frac {d\mu }{dt}\r |\) is constant, so is absorbed by \(\propto \). In the last line we use that \(ns^2=(n-1)S^2\). By Lemma 1.2.5 we identify \(\tau |x\sim \Studentt (n-1)\), as required.
-
-
7.7 We have
\(\seteqnumber{0}{C.}{3}\)\begin{align*} B &=\frac {\P [\Theta |_{\{X=x\}}\in \Pi _0]\P [\Theta \in H_1]}{\P [\Theta |_{\{X=x\}}\in \Pi _1]\P [\Theta \in H_0]} =\frac {\frac {1}{Z}\int _{\Pi _0}f_{M_\theta }(x)f_{\Theta }(\theta )\,d\theta \;\P [\Theta \in H_1]} {\frac {1}{Z}\int _{\Pi _1}f_{M_\theta }(x)f_{\Theta }(\theta )\;\,d\theta \P [\Theta \in H_0]} \\ &=\frac {\int _{\Pi _0}f_{M_\theta }(x)\frac {f_{\Theta }(\theta )}{\P [\Theta \in H_0]}\,d\theta \;} {\int _{\Pi _1}f_{M_\theta }(x)\frac {f_{\Theta }(\theta )}{\P [\Theta \in H_1]}\;\,d\theta } =\frac {\int _{\Pi _0}f_{M_\theta }(x)f_{\Theta |_{\{\Theta \in H_0\}}}(\theta )\,d\theta \;} {\int _{\Pi _1}f_{M_\theta }(x)f_{\Theta |_{\{\Theta \in H_1\}}}(\theta )\;\,d\theta } =\frac {f_{X|_{\{\Theta \in H_0\}}}(x)}{f_{X|_{\{\Theta \in H_1\}}}(x)}. \end{align*} Here, the third equality is a consequence of Theorem 3.1.2. The second-to-last inequality uses Exercise 1.8 and the final equality uses Exercise 3.6.
Chapter 8
-
-
(a,b)
-
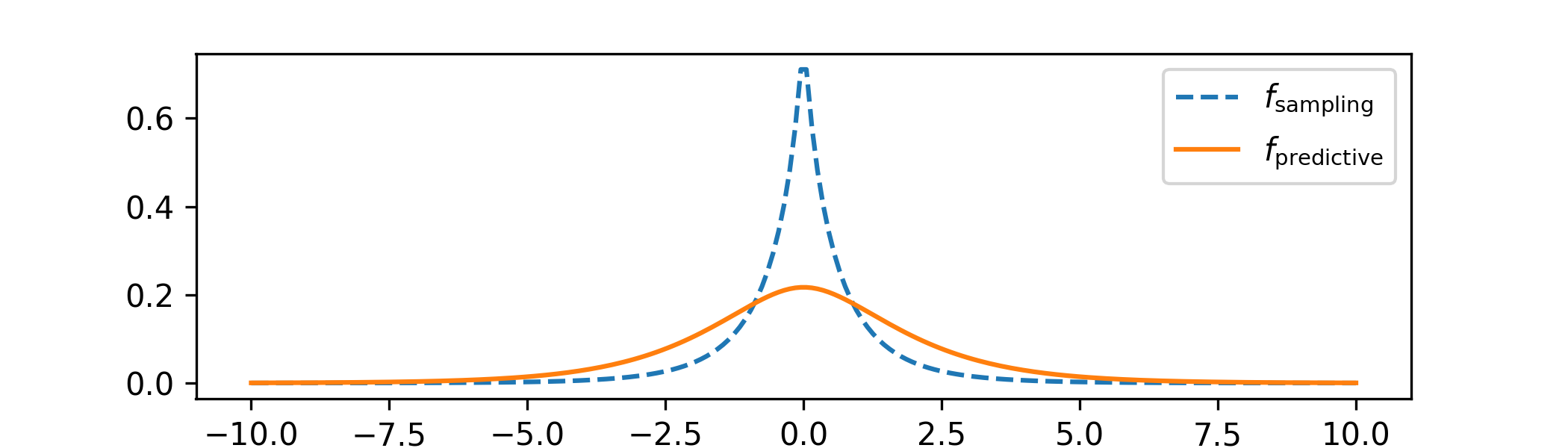
(i) We will answer both (a) and (b) here:
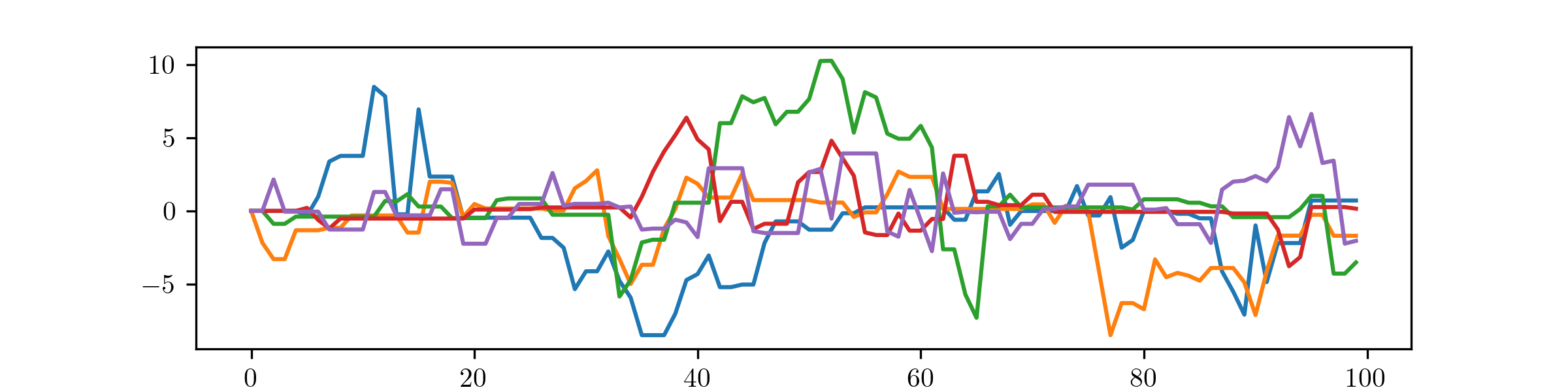
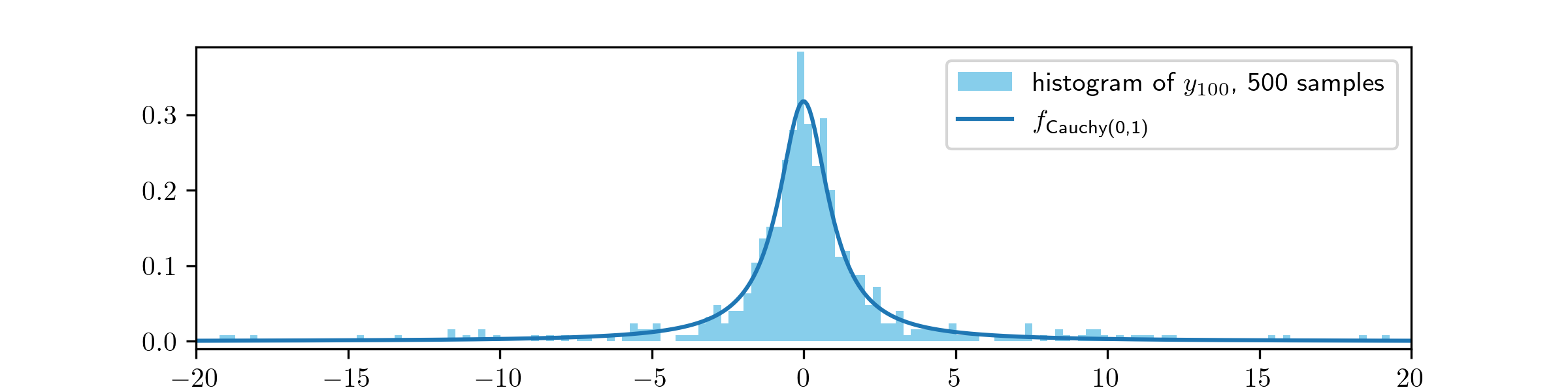
Not much has changed from Example 8.2.3 here; it is clear that the MH algorithm is making larger movements but the approximation to the \(\Cauchy (0,1)\) distribution is still quite good.
-
(ii) We obtain:
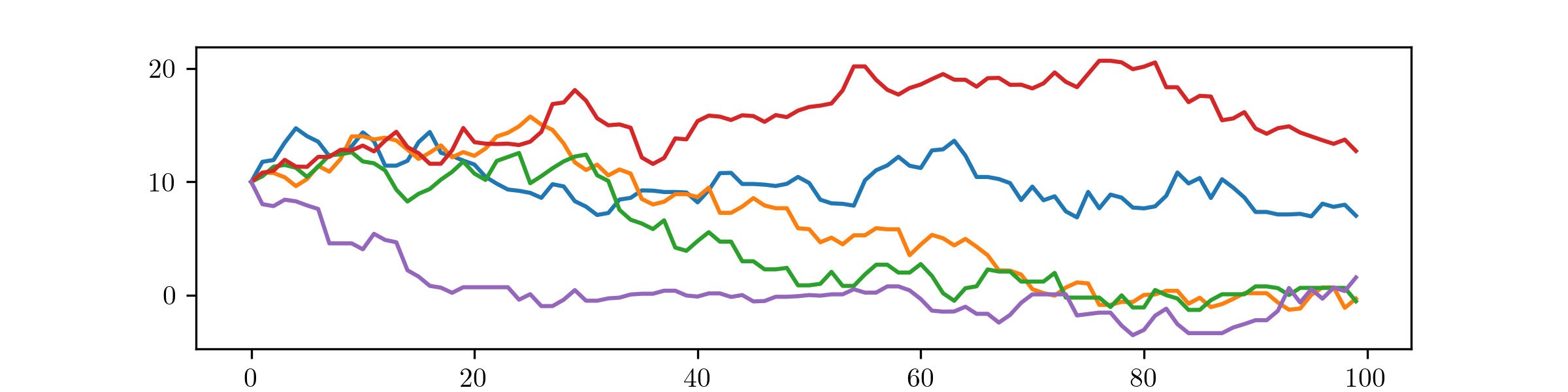
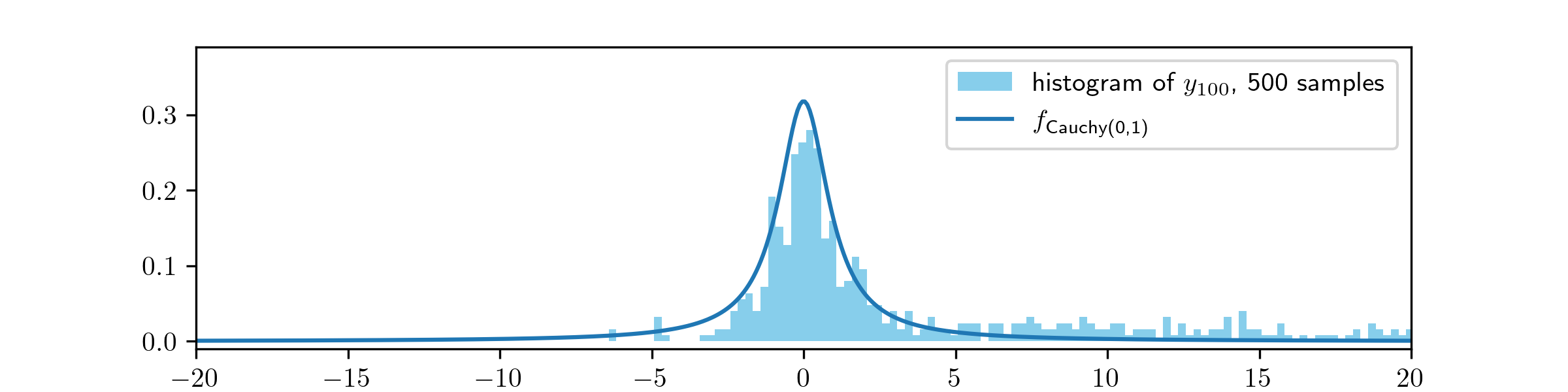
Here the MH algorithm is struggling to converge, due to being started (just) outside of the bulk of the \(\Cauchy (0,1)\) distribution that we are trying to sample. We can see in both pictures that too many samples are appearing at large values.
-
(iii) We obtain:
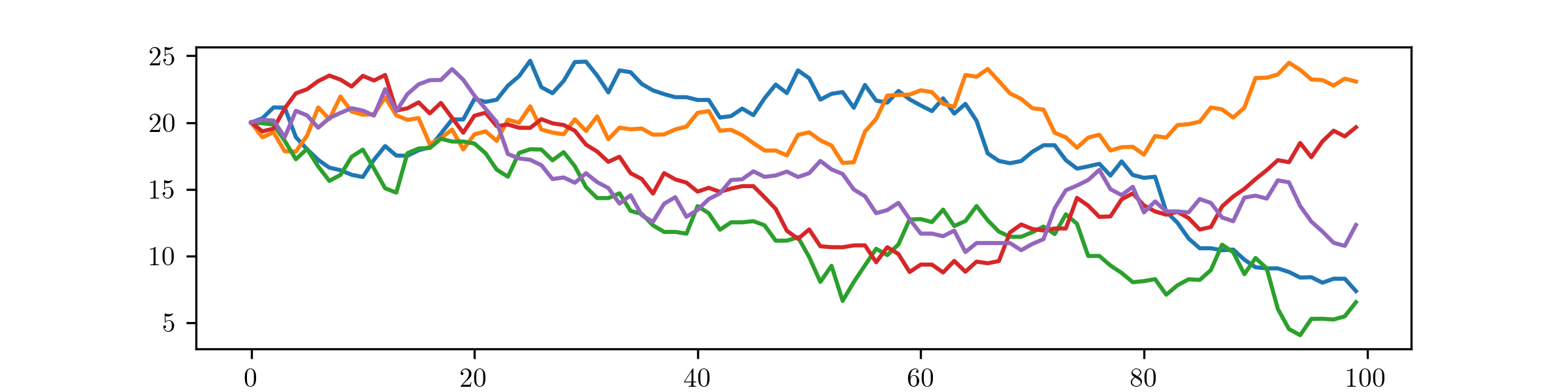
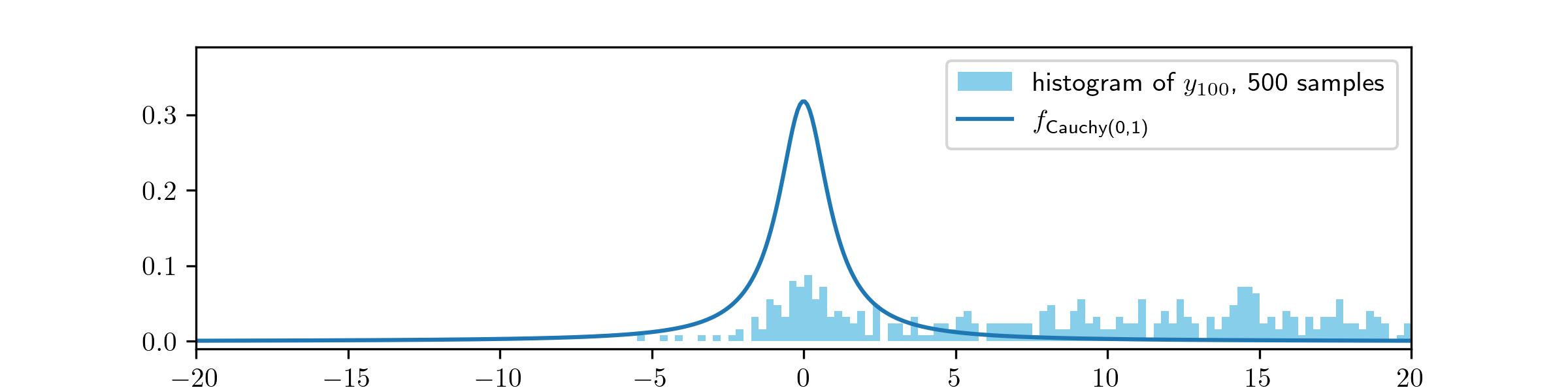
The MH algorithm is failing to converge here. The effect of the initial value is still very visible after \(100\) steps. most of the samples are too large.
-
(iv) We obtain:
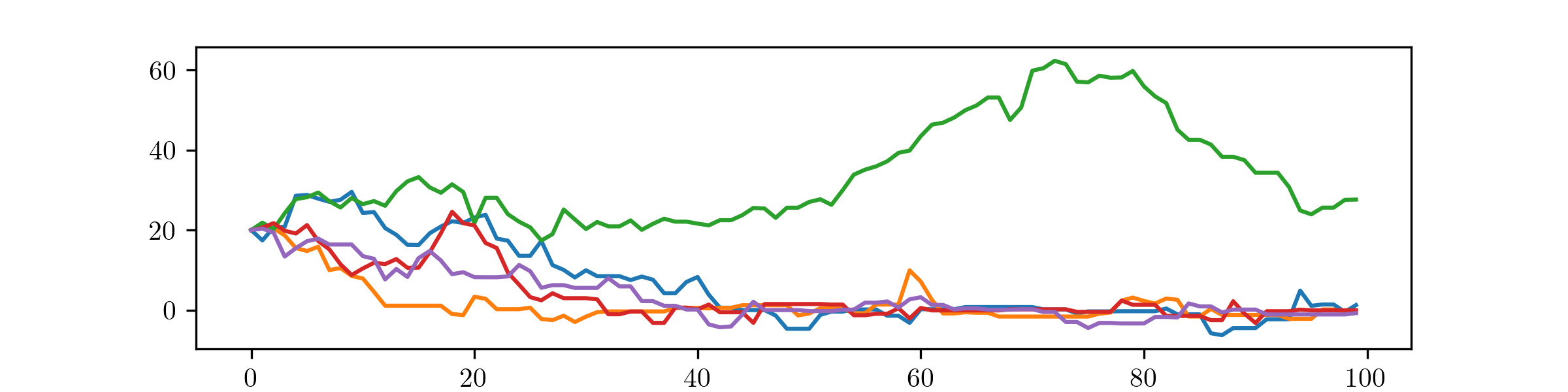
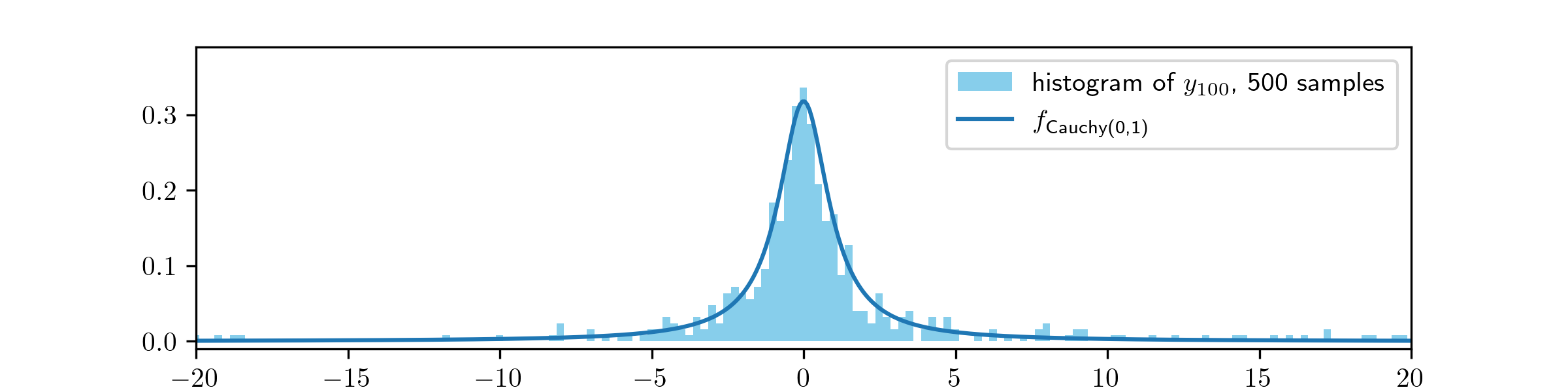
Here, by comparison to part (iii), the MH algorithm is producing good approximations to the Cauchy distributions, despite begin started at an unhelpful initial value. Increasing the step size from \(\Normal (0,1)\) to \(\Normal (0,20^2)\) has helped it to find its way back into the bulk of the distribution, quickly enough to have converged within 100 steps.
-
-
(c) Any proposals \(\wt {y}<0\) will be rejected, because
\[\alpha =\min \l \{1,\frac {f_{\Exp (1)}(\wt {y})}{f_{\Exp (1)}(y)}\r \}=\min \l \{1,\frac {0}{f_{\Exp (1)}(y)}\r \}=0\]
due the fact that \(f_{\Exp (1)}\) has range \((0,\infty )\). Hence the MH algorithm will never move below \(0\).
-
-
-
(a) The posterior density is
\(\seteqnumber{0}{C.}{3}\)\begin{align*} f(\theta |x)\propto \l (\prod _{i=1}^5\frac {\theta ^2}{x_i^2+\theta ^2}\r )\frac {1}{\theta ^2}. \end{align*} for \(\theta >1\) and zero otherwise.
There isn’t any advantage to multiplying this expression out – it won’t simplify into anything nice!
Noting that \(\frac {\theta ^2}{x^2+\theta ^2}\leq 1\), we have \(f(\theta |x)\leq \frac {1}{\theta ^2}\), which means that \(\int _{\R } f(\theta |x)\,d\theta \leq \int _1^\infty \theta ^{-2}\,d\theta <\infty \). Hence \(f(\theta |x)\) is a proper density function.
-
(b) See the files 8_mcmc.ipynb and 8_mcmc.Rmd in the solutions folder.
-
-
-
(a) In order: Definition 7.1.1, equation (7.3) and the table shortly below it, Definition 7.2.1, equation (7.5).
-
(b) In order, left column: Section 8.2.1, Section 8.2.2, Example 8.2.1 / Exercise 8.6.
In order, right column: Section 8.3.1, Section 8.4 (the algorithm is below Remark 8.4.4), Definition 8.4.3.
-
-
8.4 The point is that we need to take samples of \(Q\) in step 1 of the MH algorithm. If we already had an easy way to generate samples of \(Y\), then we wouldn’t bother using the MH algorithm anyway. So it doesn’t help to set \(Q\eqd Y\).
If we try to use the Gibbs algorithm in \(d=1\) then, strictly, our definition of the full conditionals in Definition 8.4.3 no longer works as intended because if \(\Theta =(\theta _1)\) then \(\Theta _{-1}=()\), the empty vector! However, if we try to use the same idea in \(d=1\) and take the proposal \(Q\eqd \Theta |_{\{X=x\}}\), then we run into and instance of the problem described above, here with \(Y\eqd \Theta |_{\{X=x\}}\), which is the posterior distribution that the MCMC/Gibbs algorithms are trying to sample from.
-
8.5 The full conditional distribution of \(\theta _i\) is the distribution of \(\theta _i|\theta {-i},x\). It has p.d.f. \(f(\theta _i|\theta {-i},x)\propto f(\theta )\), where on the right hand side we treat \(\theta _i\mapsto f(\theta )\) as a function of \(\theta _i\) only and \(f(\theta )\) is the density of \(\theta =(\theta _1,\ldots ,\theta _d)\).
-
-
(a) Suppose that \(X\eqd -X\). Then \(\P [X\leq x]=\P [-X\leq x]=\P [-x\leq X]\), so \(\int _{-\infty }^x f_X(u)\,du = \int _{-x}^\infty f_X{u}\,du\). Substituting \(v=-u\) in the second integral we obtain
\[\P [X\leq x]=\int _{-\infty }^x f_X(u)\,du = \int _{-\infty }^x f_X(-v)\,dv.\]
Hence the function \(v\mapsto f_X(-v)\) is the p.d.f. of \(X\), which we know is also \(f_X(x)\). Swapping \(v\) for \(x\) gives that \(f_X(x)=f_X(-x)\).
Now suppose that \(f_X(x)=f_X(-x)\). Then, using the substitution \(v=-u\),
\[\P [X\leq x]=\int _{-\infty }^x f_X(u)\,du=\int _{-\infty }^x f_X(-u)\,du=\int _{-x}^{\infty } f_X(v)\,dv =\P [-x\leq X]=\P [-X\leq x].\]
Hence \(X\eqd -X\).
Strictly, when we write \(f_X(x)=f_X(-x)\) here, we should take into account the comments about probability density functions only being defined ‘almost everywhere’ from Sections 1.1.1 and 1.2.
-
(b) By Remark 1.6.4 we have \(Q|_{\{Y=y\}}\eqd y+Z\). From the first equation we have
\[\P [Q|_{\{Y=y\}}\leq \tilde {y}]=\P [y+Z\leq \tilde {y}]=\P [Z\leq \tilde {y}-y].\]
Hence, differentiating with respect to \(\tilde {y}\), the p.d.f. of \(Q|_{\{Y=y\}}\) is
\(\seteqnumber{0}{C.}{3}\)\begin{equation*} f_{Q|_{\{Y=y\}}}(\tilde {y})=f_Z(\tilde {y}-y). \end{equation*}
Using this fact along with \(f_Z(z)=f_Z(-z)\),
\[f_{Q|_{\{Y=y\}}}(\tilde {y})=f_Z(\tilde {y}-y)=f_Z(y-\tilde {y})=f_{Q|_{\{Y=\tilde {y}\}}}(y).\]
-