Bayesian Statistics
6.2 The connection to maximum likelihood
You have already seen maximum likelihood based methods for parameter inference in previous courses. They rely on the idea that, if we wish to estimate the parameter \(\theta \), we can use that value
\(\seteqnumber{0}{6.}{4}\)\begin{equation} \label {eq:mle_def} \hat {\theta }=\argmax _{\theta \in \Pi } L_{M_\theta }(x) \end{equation}
Here \((M_\theta )\) is a family of models and \(x\) is data, and we believe that for some value(s) of the parameter the model \(M_\theta \) is reasonably similar to whatever physical process generated our data.
The value of \(\hat \theta \), which is usually uniquely specified by (6.5), is known as the maximum likelihood estimator of \(\theta \), given the data \(x\) and model family \((M_\theta )\). Graphically, it is the value of \(\theta \) corresponding to the highest point on the graph \(\theta \mapsto L_{M_\theta }(x)\). Heuristically, it is the value of \(\theta \) that produces a model \(M_\theta \) that has the highest probability (within our chosen model family) to generate the data that we actually saw.
Recall that, for a discrete random variable \(Y\), the mode is most likely single value for \(Y\) to take, or \(\argmax _{y\in \ R_Y} \P [Y=y]\) in symbols. You may be familiar with the following definition already, but we are about to need it, so we recall:
-
Example 6.2.2 For continuous random variables, \(\P [Y=y]=0\) for all \(y\). The idea here is that in this case the concept of ‘most likely value’ is best represented by the maximum of the probability density function. Let \(Y\sim \Gam (3,4)\), with p.d.f.
\[f_Y(y)=\begin {cases} 32y^{2}e^{-3y} & \text { for }y>0,\\ 0 & \text { otherwise.} \end {cases} \]
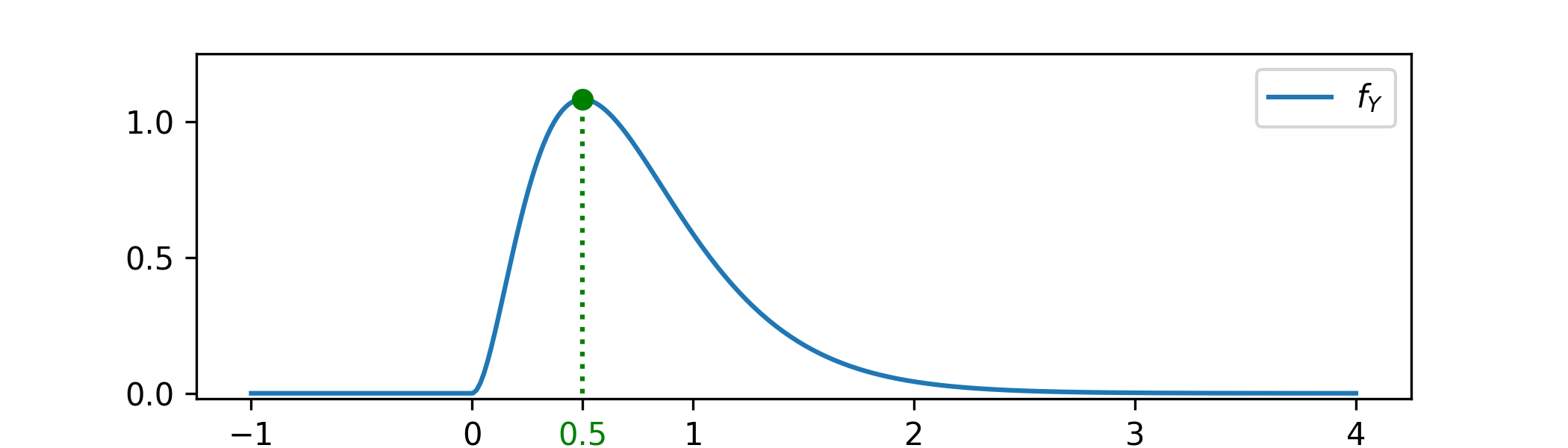
The mode is shown at its value \(y=\frac 12\). This value can be found by solving the equation \(\frac {df_Y(y)}{dy}=32\l (2ye^{-4y}+y^2(-4e^{-4y})\r )=32ye^{-4y}(2-4y)=0\) and checking that the solution \(y=\frac 12\) corresponds to a local maxima.
From Bayes’ rule we have
\[f_{\Theta |_{\{X=x\}}}(\theta )\propto L_{M_\theta }(x)f_\Theta (\theta ).\]
Comparing this equation to (6.3), we can extract a clear connection between MLEs and Bayesian inference. More precisely, the MLE approach can be viewed as a simplification of the Bayesian approach. There are two steps to this simplification:
-
1. Fix the prior to be a uniform distribution (or an improper flat prior, if necessary).
With this choice, for \(\theta \in \Pi \) we obtain the posterior density
\(\seteqnumber{0}{6.}{5}\)\begin{equation} \label {eq:posterior_from_flat_prior} f_{\Theta |_{\{X=x\}}}(\theta )\propto L_{M_\theta }(x). \end{equation}
-
2. Then, instead of considering the posterior distribution as a random variable, we approximate the posterior distribution with a point estimate: its mode.
Comparing (6.6) to (6.5), this mode is precisely the maximum likelihood estimator \(\hat \theta \).
In principle we might make either one of these simplifications without the other one, but they are commonly made together. When they are made together the methods (based on MLEs) that result are often known as ‘frequentist’ or ‘classical’ methods. We are now able to discuss how the two approaches compare:
-
• We’ve seen in many examples that, as the amount of data that we have grows, the posterior distribution tends to become more and more concentrated around a single value. In such a case, the MLE becomes a very good approximation for the posterior. This situation is common when we have plenty of data – see Section 6.2.1 for a more rigorous (but off-syllabus) discussion.
-
• If we do not have lots of data then the approximation in step 2 will be less precise and the influence of the prior will matter. In this case a well chosen prior can lead to significantly more accurate analysis.
-
• MLE methods produce a point estimate for the known parameters, which is easier to communicate but is also more open to misinterpretation. We will discuss these issues in more detail in Section 7.4, once we have seen the Bayesian version of hypothesis testing and interval estimates.
-
• If our model is not a reasonable reflection of reality, or if having more data does not help us infer parameters more accurately, then both methods become unreliable – no matter how much data we have.
You will sometimes find that statisticians describe themselves as ‘Bayesian’ or ‘frequentist’, carrying the implication that they prefer to use one family of methods over the other. This may come from greater experience with one set of methods or from a preference due to the specifics of a particular model.
To a great extent this distinction is historical. During the middle of the 20th century MLE based methods dominated statistics, because they could be implemented for complex models without the need for modern computers. Once it was realized that modern computers made Bayesian methods possible, the community that investigated these techniques needed a name and an identity, to distinguish itself as something new. The concept of identifying as ‘Bayesian’ or ‘frequentist’ is essentially a relic of that social process, rather than anything with a clear mathematical foundation.
Modern statistics makes use of both posterior distributions and (MLE or otherwise) simplifications of the posterior distribution. Sometimes it mixes the two approaches together, or chooses between them for model-specific reasons. We do need to divide things up in order to learn them, so will only study Bayesian models within this course – but in general you should maintain an understanding of other approaches too.
6.2.1 Making the connection precise \(\offsyl \)
Several theorems are known which actually prove, under wide ranging conditions, that when we have plenty of data the MLE and Bayesian approaches become essentially equivalent. These theorems are complicated to state, but let us give a brief explanation of what is known here.
Take a model family \((M_\theta )_{\theta \in \Pi }\) and define a Bayesian model \((X,\Theta )\) with model family \(M_\theta ^{\otimes n}\). This model family represents \(n\) i.i.d. samples from \(M_\theta \). Fix some value \(\theta ^*\in \Pi \), which we think of as the true value of the parameter \(\theta \). Let \(x\) be a sample from \(M_{\theta ^*}^{\otimes n}\). We write the posterior \(\Theta |_{\{X=x\}}\) as usual.
Let \(\hat \theta \) be the MLE associated to the model family \(M_\theta ^{\otimes n}\) given the data \(x\), that is \(\hat \theta =\argmax _{\theta \in \Pi }L_{M_\theta ^{\otimes n}}(x)\). Then as \(n\to \infty \) it holds that
\(\seteqnumber{0}{6.}{6}\)\begin{equation} \label {eq:bvm} \Theta |_{\{X=x\}}\approxd \Normal \l (\theta ^*,\frac {1}{n}I(\theta ^*)^{-1}\r ) \end{equation}
where \(I(\theta )\) is the Fisher information matrix defined by \(I(\theta )_{ij}=\E [\frac {\p ^2}{\p \theta _i \theta _j}\log f_{M_\theta ^{\otimes n}}(X)]\). The key point is that (6.7) says that the posterior \(\Theta |_{\{X=x\}}\) and the MLE \(\theta ^*\) are in fact very similar, for large \(n\), because of the factor \(\frac 1n\) in the variance.
Equation (6.7) is known as Laplace approximation. The mathematically precise form of this approximation, which replaces \(\approxd \) in (6.7) by the concept of convergence is distribution, is known as the Bernstein von-Mises theorem. The first rigorous proof was given by Doob in 1949 for the special case of finite sample spaces. It has since been extended under more general assumptions, notably to cover countable state spaces, but the general case (and whatever conditions it may need) is still unknown. From these results we do know that various conditions are required for (6.7) to hold. We can also identify cases in which (6.7) will fail: for example if \(M_\theta \sim \Cauchy (\theta ,1)\) then all of the terms in \(I(\theta )\) will be undefined.